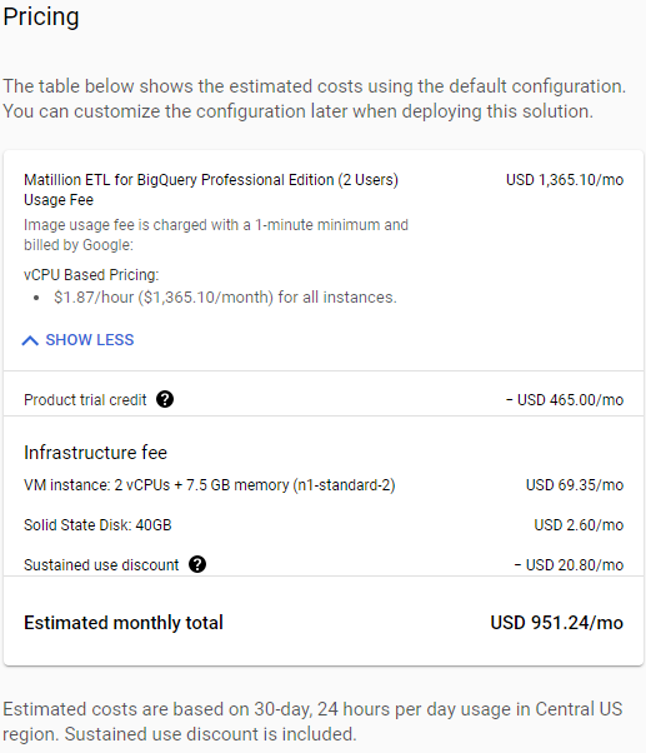
Sí, Data Mesh es realmente transformacional, pero…
¿quién me ayuda a implantarlo?
En las últimas décadas, las compañías han tratado de generar o determinar un lugar que les permita mantener, controlar y acceder a datos analíticos de su empresa y del mercado; esto con el objetivo de mejorar su negocio.
Un ejemplo típico de ello es la utilización datos del comportamiento de los clientes y el uso de sus productos para la obtención de conocimientos claros y prácticos que les permitan administrar más eficientemente el negocio, así como mejorar y crear nuevos productos.
Sin embargo, al tratar de generar estas entradas de información, los profesionales dentro de la industria se enfrentan a varios retos que pueden llegar a crear mucha frustración y caminos cerrados. Tecnologías como el Big Data o los Data Lakes han ido dando soluciones conforme se evolucionaban los modelos.
Desde mayo de 2019 con la publicación de Zhamak Dehghani, estamos viendo una nueva evolución de las prácticas para diseñar arquitecturas de datos que están cambiando estos modelos del mundo del Big Data y del Data Lake.
Hasta ahora las clásicas tres capas de ingesta, procesamiento y publicación resultaban suficientemente eficientes. Pero esa eficiencia basada en la centralización y el gobierno, hoy genera silos de conocimiento, cuellos de botella en las organizaciones complejas, falta de escalabilidad en la agregación de características y en definitiva desconexión entre los originadores de la información y los consumidores.

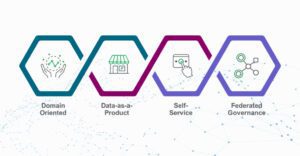
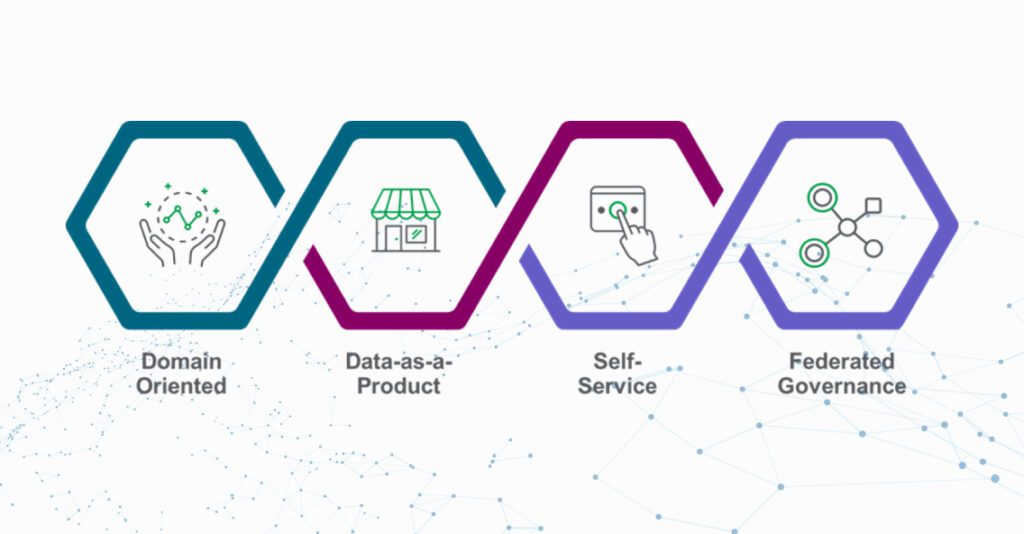
El enfoque de Data Mesh es más que una metodología, un paradigma para la integración de una arquitectura de datos que descentraliza la propiedad de los dominios de datos, y al mismo tiempo define productos de datos analíticos, en un entorno que equilibra le gestión gobernada y la autonomía de los citados dominios. El paradigma Data Mesh, que hereda conceptos de la filosofía DDD (Data Driven Design), identifica cuatro conceptos como base de su modelo:
- Los dominios como dueños de los datos, dominios cuya concepción inicial puede aproximarse a los dominios de negocio, y es donde se definen las entidades de datos y las relaciones con otros dominios para su consumo.
- Los datos como producto, y como tal, pasan a ser susceptibles de proveer niveles de servicio. Pasando la responsabilidad de los mismo de la plataforma al equipo responsable del dominio.
- La plataforma como autoservicio, automatizada y asegurando la independencia y la autonomía de cada dominio.
- El gobierno federado, que asegure las decisiones próximas a los dominios pero que a la vez establezca las reglas de mínimos que aseguren la interoperabilidad entre ellos.

Este nuevo modelo supone además un cambio organizacional para asegurar su éxito. Los dominios además de dueños de sus productos de datos deben ser autónomos a la hora de desarrollar nuevos productos tanto para consumo propio como de otros dominios. Y, además, deben asegurar el consumo y el gobierno de los productos de datos. Y para ello deben contar con el conocimiento necesario de las plataformas, de forma que se asegure su autonomía, descargando del equipo de plataforma ciertas responsabilidades de gestión de dichos productos de datos.
Estos cambios a modelos más ágiles, pero a la vez de responsabilidades distribuidas, son fundamentalmente culturales, y requieren contar con equipos maduros capaces de asumir de forma autónoma la nueva distribución de responsabilidades, los nuevos procesos y su gobierno.
Vale, pero ¿por dónde empiezo?

Hoy nuestros clientes se enfrentan aún a un modelo en proceso de maduración en el mercado que genera muchas cuestiones de enfoque inicial. Pese a que parece claro que ese equilibrio entre gobernabilidad y autonomía puede aportar eficiencias, el modelo metodológico de Data Mesh es aún emergente, y por descontado requiere del soporte de equipos senior técnicos y de negocio con alto nivel de madurez, capaces de tomar decisiones ágiles a lo largo del proceso, que no puede entenderse como puntual, sino de medio o largo plazo.
Bluetab a lo largo de los proyectos en entornos de clientes, ha desarrollado una metodología basada en experiencias de implantación de modelos de gobierno que aseguran un enfoque adecuado de este proceso de transformación. Una metodología muy operativa enfocada, más allá de un trabajo teórico, a la aplicación práctica de los modelos a los diferentes ecosistemas de nuestros clientes.
Esto se lleva a cabo estableciendo primero, casos de uso controlados y relevantes que permitan la visión desde la generación hasta el consumo de la información requerida por negocio, posteriormente, definiendo el plan de despliegue a los demás casos de uso de la organización y, finalmente y en paralelo, actuando sobre los requerimientos del cambio organizacional con comunicación y acciones específicas que habiliten la gestión del cambio.
Esta metodología inicia con el apoyo a la definición del contexto de dominios y la identificación de un primer caso de uso (MVP) que permita la visión end-to-end de los requerimientos a lo largo de los cuatro elementos, los citados dominios, los productos de datos y sus interdependencias, el modelo de autoservicio y las arquitecturas habilitadoras, y los requisitos de un gobierno no limitativo.

Una vez establecido dicho MVP e implantado, se genera el entendimiento global necesario para la definición de un plan de despliegue capaz de escalar a todo el ecosistema con éxito. Un plan que mediante métodos ágiles irá adaptándose a las diferentes particularidades y al propio cambio de requerimientos de negocio en el tiempo.
Pero el valor de nuestra aportación está en que, a lo largo de nuestros proyectos, hemos desarrollado herramientas prácticas de automatización para la implantación práctica de los modelos, aceleradores que Bluetab pone a disposición de sus clientes y que aseguran la optimización de los tiempos en el proceso de despliegue y su posterior evolución, y el apoyo a los clientes para una definición del modelo adecuado a su ecosistema y adaptada a sus requerimientos de negocio. Todo ello soportado por una estrategia de medición del valor aportado mediante datos objetivados KPIs.

En la definición de un ecosistema orientado a dominios es crucial el entendimiento del negocio y de la realidad de los consumos de datos dentro de cada una de las estructuras organizativas. A partir de ahí se puede establecer el debate para una definición de dominios consistente, acordada y de largo plazo.
Una herramienta como nuestra Matriz de Convergencia, donde se cruzan consumos, proyectos, orígenes, etc., permite una evaluación objetiva y profundizar en un mismo entendimiento y nomenclatura común en la organización. A partir de ahí, la definición del primer caso de uso y la priorización en el plan de escalado posterior se realiza de forma consistente.
En la generación de productos de datos, hay varios factores relevantes además del entendimiento y los modelos del consumo seguramente mediante API´s y una estrategia de disponibilización con la definición de mínimos requeribles. Uno de esos factores es la evaluación de la aportación del valor de dichos productos, y otro la estrategia de comunicación y comunicación/disponibilización a los demás dominios.
Para todo ello nuestro asset de gobierno del dato, Truedat, posibilita una solución que cubre desde el metadatado, a la generación de un Marketplace común, asegurando el control de los mínimos de gestión.
En la gestión del gobierno federado y el equilibrio entre el control y la autonomía de los dominios, nuestra Matriz de Madurez es fundamental para la evaluación del nivel de dicha madurez y el establecimiento del programa que cubra el gap de requerimientos. Y una vez establecido el programa, esta misma suite de servicios, Truedat, aporta capacidades adecuadas de calidad o trazabilidad que aseguran la implementación de las reglas que definan los propietarios en los dominios y la gestión técnica del end-to-end del ciclo de vida del dato.
Y finalmente en el desarrollo de una plataforma automatizada y enfocada al autoservicio de los dominios, nuestros modelos de arquitecturas, así como nuestras herramientas de despliegue automático de servicios y nuestros modelos de despliegue de estrategias Devops y MLops, aseguran una implantación optimizada de la estrategia y un time-to-market eficiente en su evolución de requerimientos.
La implantación de una estrategia Data Mesh genera aún muchas dudas sobre cómo abordarla en entornos complejos en el que coexisten diferentes arquitecturas, modelos de datos y requerimientos de consumo. Nuestro enfoque metodológico, más dirigido al desarrollo práctico de la puesta en marcha de cada uno de los pilares de la estrategia, puede asegurarte un despliegue ágil y en unos tiempos asumibles. De esta forma tanto las áreas técnicas como negocio pueden obtener el retorno de valor en los plazos requeridos.
Síguenos y en próximos artículos entraremos en mayor detalle sobre cómo aterrizar de forma práctica y eficiente en este nuevo paradigma Data Mesh.

Autores


Alvar Noe Arellanos
Business & IT Strategy Professional

Juan Manuel Sanchez
Data Strategy

Armando Camargo
Data Governance Manager

Jesus Saavedra
BI Manager

¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar