5 common errors in Redshift

5 common errors in Redshift

What is Redshift?
Amazon Redshift is a very fast, cloud-based analytical (OLAP) database, fully managed by AWS. It simplifies and enhances data analysis using standard SQL compatible with most existing BI tools.
The most important features of Amazon Redshift are:
- Data storage in columns: instead of storing data as a series of rows, Amazon Redshift organises the data by column. Because only the columns involved in queries are processed and the data in columns are stored sequentially on storage media, column-based systems require much less I/O, which greatly improves query performance.
- Advanced compression: column-based databases can be compressed much more than row-based databases because similar data is stored sequentially on disk.
- Massively Parallel Processing (MPP): Amazon Redshift automatically distributes the data and query load across all nodes.
- Redshift Spectrum: lets you run queries against exabytes of data stored in Amazon S3.
- Materialized views: subsequent queries that refer to the materialized views use the pre-calculated results to run much faster. Materialized views can be created based on one or more source tables using filters, projections, inner joins, aggregations, groupings, functions and other SQL constructs.
- Scalability: Redshift has the ability to scale its processing and storage by increasing the cluster size to hundreds of nodes.
Amazon Redshift is not the same as other SQL database systems. Good practices are required to take advantage of all its benefits, so that the cluster will perform optimally.
1. Working as if it were a PostgreSQL
A very common mistake made when starting to use Redshift is to assume that it is simply a vitamin-enriched PostgreSQL and that you can start working with Redshift based on a schema compatible with that. However, you could not be more wrong.

Although it is true that Redshift was based on an older version of PostgreSQL 8.0.2, its architecture has changed radically and has been optimised over the years to improve performance for its strictly analytical use. So you need to:
- Design the tables appropriately.
- Launch queries optimised for MPP environments.
Design the tables appropriately
When designing the database, bear in mind that some key table design decisions have a considerable influence on overall query performance. Some good practices are:
- Select the optimum data distribution type:
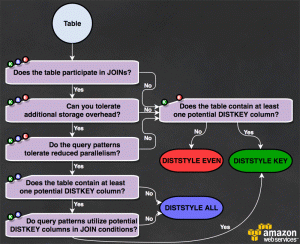
- For fact tables choose the
DISTKEYtype. This will distribute the data to the various nodes grouped by the chosen key values. This will enable you to performJOINtype queries on that column very efficiently. - For dimension tables with a few million entries, choose the
ALLtype. It is advisable to copy those tables commonly used in joins of dictionary type to all the nodes. In that way theJOINstatement with much bigger fact tables will execute much faster. - When you are not clear on how you are going to query a very large table or it simply has no relation to the rest, choose the
EVENtype. The data will be distributed randomly in this way.
- For fact tables choose the
- It uses automatic compression, allowing Redshift to select the optimal type for each column. It accomplishes this by scanning a limited number of items.

Use queries optimised for MPP environments
As Redshift is a distributed MPP environment, query performance needs to be maximised by following some basic recommendations. Some good practices are:
- The tables need to be designed considering the queries that will be made. Therefore, if a query does not match, you need to review the design of the participating tables.
- Avoid using
SELECT *.and include only the columns you need. - Do not use cross-joins unless absolutely necessary.
- Whenever you can, use the
WHEREstatement to restrict the amount of data to be read. - Use sort keys in
GROUP BYandSORT BYclauses so that the query planner can use more efficient aggregation.
2. Loading data in that way
Loading very large datasets can take a long time and consume a lot of cluster resources. Moreover, if this loading is performed inappropriately, it can also affect query performance.
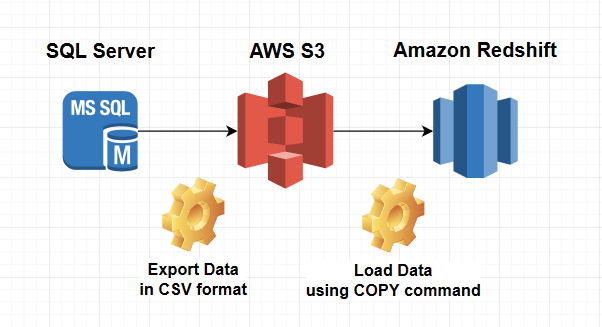
This makes it advisable to follow these guidelines:
- Always use the
COPYcommand to load data in parallel from Amazon S3, Amazon EMR, Amazon DynamoDB or from different data sources on remote hosts.
copy customer from 's3://mybucket/mydata' iam_role 'arn:aws:iam::12345678901:role/MyRedshiftRole'; - If possible, launch a single command instead of several. You can use a manifest file or patterns to upload multiple files at once.
- Split the load data files so that they are:
- Of equal size, between 1 MB and 1 GB after compression.
- A multiple of the number of slices in your cluster.
- To update data and insert new data efficiently when loading it, use a staging table.
-- Create an staging table and load it with the data to be updated
create temp table stage (like target);
insert into stage
select * from source
where source.filter = 'filter_expression';
-- Use an inner join with the staging table to remove the rows of the target table to be updated
begin transaction;
delete from target
using stage
where target.primarykey = stage.primarykey;
-- Insert all rows from the of the staging table.
insert into target
select * from stage;
end transaction;
-- Drop the staging table.
drop table stage; 3. Dimensioning the cluster poorly
Over the years we have seen many customers who had serious performance issues with Redshift due to design failures in their databases. Many of them had tried to resolve these issues by adding more resources to the cluster rather than trying to fix the root problem.
Due to this, I suggest you follow the flow below to dimension your cluster:
- Collect information on the type of queries to be performed, data set size, expected concurrency, etc.
- Design your tables based on the queries that will be made.
- Select the type of Redshift instance (DC2, DS2 or RA3) depending on the type of queries (simple, long, complex…).
- Taking the data set size into account, calculate the number of nodes in your cluster.
# of Redshift nodes = (uncompressed data size) * 1.25 / (storage capacity of selected Redshift node type) « For storage size calculation, having a larger margin for performing maintenance tasks is also recommended »
- Perform load tests to check performance.
- If it does not work adequately, optimise the queries, even modifying the design of the tables if necessary.
- Finally, if this is not sufficient, iterate until you find the appropriate node and size dimensioning.
4. Not making use of workload management (WLM)
It is quite likely that your use case will require multiple sessions or users running queries at the same time. In these cases, some queries can consume cluster resources for extended periods of time and affect the performance of the other queries. In this situation, simple queries may have to wait until longer queries are complete.
By using WLM, you will be able to manage the priority and capacity of the different types of executions by creating different execution queues.
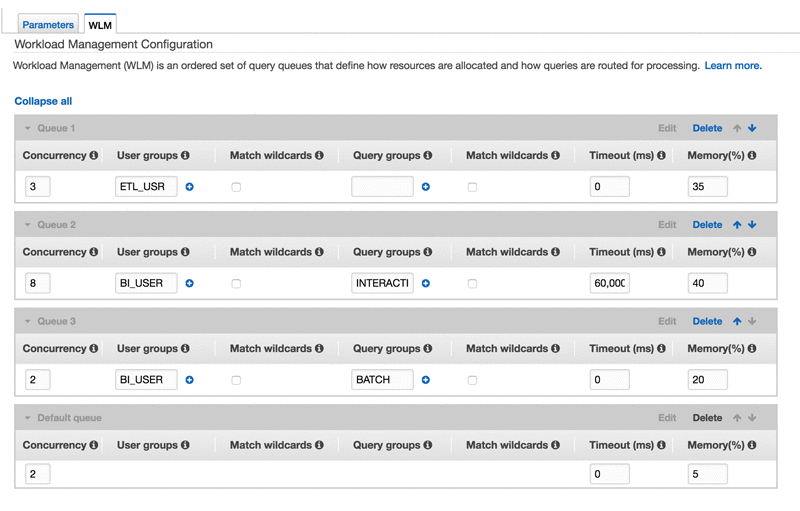
You can configure the Amazon Redshift WLM to run in two different ways:
- Automatic WLM: the most advisable manner is to enable Amazon Redshift so that it manages how resources are split to run concurrent queries with automatic WLM. The user manages queue priority and Amazon Redshift determines how many queries run simultaneously and how much memory is allocated to each query submitted.
- Manual WLM: alternatively, you can configure resource use for different queues manually. At run time, queries can be sent to different queues with different user-managed concurrency and memory parameters.
How WLM works
When a user runs a query, WLM assigns the query to the first matching queue, based on the WLM queue assignment rules.
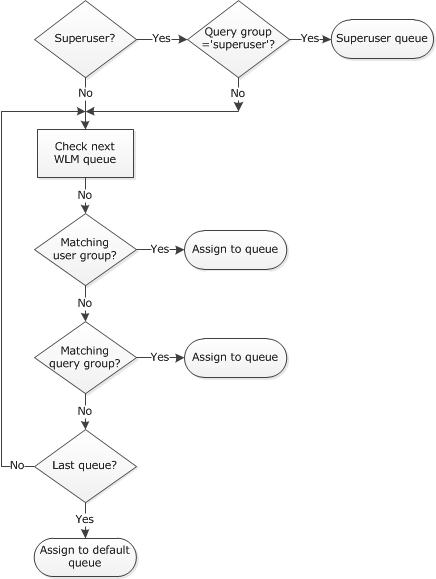
- If a user is logged in as a superuser and runs a query in the query group labelled superuser, the query is assigned to the superuser queue.
- If a user belongs to a listed user group or runs a query within a listed query group, the query is assigned to the first matching queue.
- If a query does not meet any criterion, the query is assigned to the default queue, which is the last queue defined in the WLM configuration.
5. Neglecting maintenance.
Database maintenance is a term we use to describe a set of tasks executed with the intention of improving the database. There are routines to help performance, free up disk space, check data errors, check hardware faults, update internal statistics and many other obscure (but important) things.
In the case of Redshift, there is a mistaken feeling that as it is a service fully managed by Amazon, there is no need for any. So you create the cluster and forget about it. While AWS makes it easy for you to manage numerous tasks (create, stop, start, destroy or perform back-ups), this could not be further from the truth.

The most important maintenance tasks you need to perform in Redshift are:
- System monitoring: the cluster needs monitoring 24/7 and you need to perform periodic checks to confirm that the system is functioning properly (no bad queries or blocking, free space, adequate response times, etc.). You also need to create alarms to be able to anticipate any future service downtimes.
- Compacting the DB: Amazon Redshift does not perform all compaction tasks automatically in all situations and you will sometimes need to run them manually. This process is called
VACUUMand it needs to be run manually to be able to useSORT KEYSof theINTERLEAVEDtype. This is quite a long and expensive process that will need to be performed, if possible, during maintenance windows. - Data integrity: as with any data loading, you need to check that the ETL processes have worked properly. Redshift has system tables such as
STV_LOAD_STATEwhere you can find information on the current status of theCOPYinstructions in progress. You should check them often to confirm that there are no data integrity errors. - Detection of heavy queries: Redshift continuously monitors all queries that are taking longer than expected and that could be negatively impacting service performance. So that you can analyse and investigate those queries, you can find them in system tables as
STL_ALERT_EVENT_LOGor through the AWS web console itself.
Do you want to know more about what we offer and to see other success stories?
DISCOVER BLUETAB
Share on twitter
Share on linkedin
Álvaro Santos
Senior Cloud Solution Architect
My name is Álvaro Santos and I have been working as Solution Architect for over 5 years. I am certified in AWS, GCP, Apache Spark and a few others. I joined Bluetab in October 2018, and since then I have been involved in cloud Banking and Energy projects and I am also involved as a Cloud Master Partitioner. I am passionate about new distributed patterns, Big Data, open-source software and anything else cool in the IT world.
SOLUTIONS, WE ARE EXPERTS
DATA STRATEGY
DATA FABRIC
AUGMENTED ANALYTICS
You may be interested in