LakeHouse Streaming on AWS with Apache Flink and Hudi (Part 1)

Alfonso Jerez
AWS Cloud Engineer
Introduction
Every day the ingestion and processing of Near Real Time (NRT) data streams becomes more necessary. Business requirements are becoming more demanding in terms of processing times and availability of the latest data and this article aims to address this issue.
Using the AWS cloud and a serverless approach, this article will deploy an application capable of ingesting data streams and processing them in NRT, writing their result in a
LakeHouse in such a way that ACID (Atomic, Consistent, Isolated and Durable) operations can be performed on them. An architecture will be deployed in which data is ingested with Locust, processed with Flink and finally written in Hudi and JSON formats.
Locust is a Python framework to perform Load Testing in an easy and scalable way. The advantages offered by Locust are the ability to define this user behavior with a general purpose language and its ease of scalability.
Flink has become a reference framework in the field of distributed processing on data streams. It is characterized by its stream processing orientation (although it can also execute batch processes), its processing speed and its memory efficiency. There are other popular frameworks in the industry, such as Spark Streaming and Storm, the architecture section will discuss why Flink was ultimately chosen.
Finally, Hudi is a transactional file format that provides the capabilities of a database and DataWarehouse to the Data Lake. Hudi gives the ability to leave behind the concepts of batching and replace it with an incremental processing perspective. Like the other technologies used in this article, it is described in detail below.
All the code used in this article, both IaC and Python, can be found in our repository[1] on Github.
In future articles
Multiple articles will use this one as a basis for discussing the following topics:
- Comparison in terms of processing efficiency, writing and reading files and costs in JSON vs Hudi.
- Comparison of MOR vs COW, in addition to the consumption of these tables by the different types of queries (Snapshot, Read Optimized, Incremental).
- Scalability.
- Other forms of data mining, such as Redshift or Pinot.
Architecture
Below you can see the high-level architecture that will be deployed:
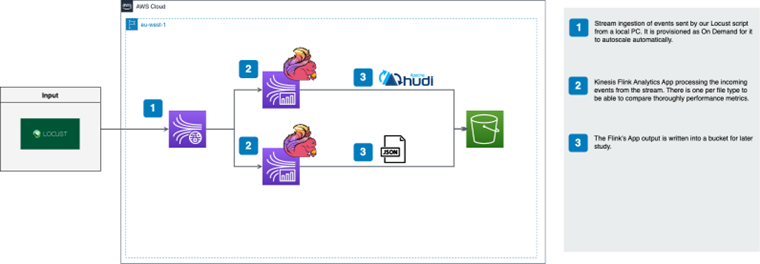
As you can see, Locust is used as a Load Testing tool to send synthetic data to our application. These will be ingested through a Kinesis Stream provisioned in On Demand mode, so the stream will scale automatically. The alternative to the On Demand mode is the Provisioned mode, where we must specify the number of shards (component in which the stream is divided), with which we want to provision the stream. The differences and particularities of these two modes will be explained in more detail in the Kinesis section.
The input stream is read by two Kinesis Analytics Flink applications. As mentioned in the next steps section, the reason to have two independent applications writing in Hudi and JSON respectively is to make a comparison in future articles in terms of efficiency. Finally the data will be hosted in S3, the AWS object storage service.
The particularity of the Kinesis Analytics Flink application is that it is serverless, that is, it abstracts the developer from the complexity of configuring and deploying a Flink cluster. This application must be assigned KPUs or Kinesis Processing Units and a jar with the Flink library and the necessary connectors to be able to deploy it correctly. All these concepts will be explained in the following sections.
The alternative to this serverless perspective with a managed service on AWS is the complete administration of the application by the developer, who can use tools such as Kubernetes or EKS (Kubernetes managed on AWS) to deploy this Flink application in a cluster. The advantages of this second alternative would be to be able to configure both the cluster (number of nodes, memory, CPU, hard disk, etc…) and the Flink application (disaster recovery management, metadata management, etc…) with a much greater degree of detail. In this article, the first alternative was chosen because of its simplicity and ease of use when learning about the Flink framework.
Locust
The first piece in the data ingestion pipeline is the Locust component written in Python. Unlike other frameworks available on the market such as JMeter, Locust gives us the ability to write simple code with Python instead of using a domain-specific language or user interface.
In addition, Locust is event-driven and uses greenlet[2], which gives it the ability to manage the capacity of several thousand users with a single processor thread. For example, in the case of JMeter, one thread is needed for each user, which poses a scalability problem for cases where a high number of users are needed.
Locust has several possibilities when it comes to running and scaling, being able to run locally for less data-intensive applications or deploy to a Kubernetes cluster by creating a Docker image from Locust code.
As for clients and systems to send data to, Locust provides a built-in HTTP client. In case you want to send events to other systems, like the one in this article, you can always write a custom client thanks to the advantage of being a Python framework.
In addition, Locust also provides a web interface so that you can check the progress of your data submission in real time. For all these reasons it has been decided to use this technology in this article.
Kinesis Data Analytics
For data ingestion, Kinesis Data Streams, a fully managed and serverless data streaming service offered by AWS, will be used. A Kinesis Stream consists of a logical grouping of shards, which represent the fundamental unit of capacity of a stream and are processed in parallel. Each shard provides the stream with 1 MB/s or 1,000 events per second write and 2 MB/s read. The events will be distributed among the stream shards according to their partitioning key, so it is important that the partitioning is homogeneous to avoid a bias in the distribution and occurrence of hot shards. There are two modes of capacity provisioning:
- On Demand – the number of shards is automatically managed to accommodate the load, ensuring optimal performance without the need for manual adjustments.
- Provisioned – you must specify the number of shards for the stream based on the expected load.
For simplicity, and because it is suitable for our use case, we will opt for the On Demand mode. This will automatically accommodate the number of shards to the amount of data generated by our Locust application.
To read and process the data ingested through Kinesis Data Streams, another service of the Kinesis family, Kinesis Data Analytics (KDA), will be used. This service is offered in two flavors:
- Kinesis Analytics SQL – Enables the creation of streaming data processing applications using SQL. This service is considered deprecated in favor of the KDA for Apache Flink service.
- Kinesis Analytics for Apache Flink – Provides a way to deploy a Flink cluster managed by AWS. Using Flink empowers the creation of more advanced and better performing applications.
A Flink application consists of a series of parallel processing tasks, also known as operators, which are connected in a Directed Acyclic Graph (DAG). The data stream is processed by this DAG, with each operator performing a specific operation on the data.
KDA allocates computing power for our application in the form of Kinesis Processing (KPUs), each equivalent to 1 vCPU and 4GB of RAM. The number of KPUs for the application is determined by specifying two parameters:
- Parallelism – Number of tasks that can be executed concurrently.
- ParallelismPerKPU – Number of tasks that can run on a single KPU.
The total number of KPUs of the application is given by Parallelism / ParallelismPerKPU. It is possible to deploy this service with automatic autoscaling, which will automatically adjust the number of KPUs based on CPU consumption to accommodate demand.
The costs[3] of Amazon Kinesis Analytics are based on a pay-per-use model, based on the Kinesis Processing Units consumed. In addition, a cost is assumed for the storage used by the application and its backups.
Flink
Delving deeper into the Flink application, one of the most important features is the ability to be resilient to failures. To this end, Flink incorporates a checkpointing system whereby a snapshot of the application and its state is taken and stored in remote storage in case the application needs to be recovered.
The checkpointing process of a Flink application is designed to be resilient and efficient. Flink can make use of different backends to store the state of the application. The simplest would be the Java Virtual Machine’s own memory, and while this offers low latency and simpler management, scaling and capacity issues can quickly arise that make it undesirable for production environments. This is why it is common to use RocksDB as a backend for Flink, a high-performance, scalable and fault-tolerant key-value database. Additionally KDA stores these snapshots in S3 for an extra layer of durability.
For the purpose of this blog, a simple application has been developed for real-time data ingestion and subsequent saving to S3. Flink offers two APIs through which you can develop an application:
- DataStream API – It is an API based on the concept of streams. It offers low-level control of the application with the disadvantage of requiring more effort from the developer.
- Table API – This API is based on the concept of tables. It provides a declarative way to develop the application by using SQL expressions. It leads to a loss of control over the details of the application in favor of being much simpler.
For this use case the Table API will be used for its simplicity, but it is equally compatible with the use of the DataStream API.
Deploying the application with Kinesis Data Analytics requires only to define the entry point of the application code and provide an uber jar with all the application dependencies. It is fitting to explain the dependencies used for this application, as it is usually one of the major pain points when developing a Flink application:
- SQL connector for Kinesis – Fundamental connector for our Flink application to be able to read from a Kinesis Stream.
- S3 Filesystem for Hadoop – Allows the application to operate on top of S3.
- Hudi Bundle – Package provided by Hudi developers, with all the necessary dependencies to work with the technology.
- Hadoop MapReduce Client Core – Additional dependency required for writing to Hudi to work correctly in KDA. It is possible that in future versions of the Hudi Bundle this dependency will not be needed.
The application is prepared to write data both in JSON format and in Hudi MoR or CoW tables (which will be explained in detail in the next section). Both the application code and the infrastructure are available in the repository.
Hudi
Concepts
Hudi is presented as a source of Open Source storage at the data format level. Like other solutions such as Iceberg or Delta Lake, it offers some of their existing properties such as ACID (Atomicity, Consistency, Isolation and Durability) transaction support, processes focused on optimizing read/write tasks, incremental data updates and others that will be explained below. It is important to highlight that these could not be achieved by means of Avro and Parquet format files.
Hudi’s features are as follows:
- ACID transactions: One of the main advantages offered by Apache Hudi is the support for ACID transactions, enabling write operations to be atomic and consistent. It also provides data isolation and durability, ensuring data integrity and system consistency. How the various forms of storage make this possible and the advantages they offer will be discussed in more detail later.
- Incremental Pipelines: the clustering of events based on business variables allows data deletion/update tasks to be performed more efficiently if they are indexed together even if they have not occurred in the same time frame.
- Streaming Ingest: Hudi allows to obtain computationally lighter workloads through Upserts that resort to an optimized indentation[4] by file groups, which makes writing tasks (Update/Append/Delete) more efficient. This allows many Hudi-based applications not to be deduplicated.
- Queries of previous data states – Time Travel: Hudi allows updating and consulting information from past partitions without the need to reprocess or include major temporary partitions. This ensures that events sent later are not processed and are correctly stored.
- Concurrent write tasks: by means of OCC (Optimistic Concurrency Control[5]), many of the tasks such as Upsert and Insert can be performed correctly even if they are performed simultaneously.
When analyzing how Hudi proceeds to store the ingested events, these are grouped by partitions and these in turn are grouped into groups of files. The latter are assigned a unique file_id for each group in which the base file is found, in parquet format, which arises after an action, either a commit or compaction, and the log file which is where all the updates are registered (event version tracking).
Table Types and Queries
Hudi offers 2 types of tables depending on the business need, this has an impact in terms of performance and limitation of certain functionalities as we will see in more detail:
Copy on Write (COW)
A storage system whereby the tasks of updating, deleting or recording new data are performed directly on the log file (delta file) and a new snapshot is created that includes a complete copy of the updated dataset, including a new version of the base file and a delta file containing the changes made in that operation.
It is not until data compacting (scheduled or upon reaching a defined data size) that the delta files are combined with the most recent version of the complete dataset, creating a new complete file where the delta files that are no longer needed are removed and the index file is updated so that it can access the data in the compacted file.
This storage system is especially recommended for use cases where read tasks are more frequent than write tasks as it does not require additional data transformations when reading data.
The Timeline of the main files is shown below when the various writing tasks are performed:
| task | NEW Base File | Delta File | Index File | Snapshot |
|---|---|---|---|---|
| New event | The record is written to the base file | No delta file is created | The index file is updated with the new record | No new snapshot is created |
| Updating existing registration | The updated record is written to a new delta file | the updated record is written to the corresponding delta file | The index file is updated with the updated version of the registry | No new snapshot is created |
| De-registration | Record is not deleted form the base file | A deletion flag is written to a new delta file | The index file is updated with the deletion flag | No new snapshot is created |
| Compacting delta file | The delta file are merged into a new base file | A new delta file is created containing the pending updates after the last compacting | A new index file is created containing all index entries of the merged files | A new snapshot is created reflecting the current state of the data after compaction |
Merge On-Read (MOR)
In this case, separate delta files are not used as in the Copy-on-Write (COW) model. Instead, changes are written directly to the existing data files (base files). In tasks where record updates are performed, these new records are added to the base file, and in the case of deletions, these are marked as such in the base file, in both cases these changes are recorded in the index file, until compaction is performed. It is in this operation that all updates are applied to the records in the corresponding base file and deletes the previous versions of the updated records.
This alternative is specialized in performing queries of versioned historical data and NRT transformations and analysis of large volumes, since it is possible to do so without having to copy the data to another location on disk. In addition to being optimal for use cases where write tasks are concurrent as it is more efficient since it is not necessary to perform additional data transformations during the write, although it has a lower tolerance to failure since in case the log file is corrupted it can generate loss of data versions.
The Timeline of the main files is shown below when the various writing tasks are performed:
| Task | NEW Base File | Delta File | Index File | Snapshot |
|---|---|---|---|---|
| New event | The record is written to the new base file | No delta file is created | The index file is updated with the new record | No new snapshot is created |
| Updating existing registration | The updatad record is written to the new base file | The updated record is written to a new delta file | The index file updated with the updated version of the registry | No new snapshot is created |
| De-registration | The deleted record is not written to the new base file | A deletion flag is written to a new delta file | The index file is updated with the deletion flag | No new snapshot is created |
| Compacting delta files | The delta file is merged into the new base file | No new delta file is created | A new index file is created containing all index entries of the merged files | A new snapshot is created reflecting the current state of the data after compaction |
As a summary, a comparison of the main performance metrics between Copy on-Write and Merge on-Read is made:
| COW | MOR | |
|---|---|---|
| Writing cost |
Higher |
Lower |
| Latency |
Higher |
Lower |
| Query Performance |
Lower |
Slower before compaction Igual tras compactación |
- Write: COW has a higher write cost than MOR because each time a write operation is performed (either adding a new record or updating an existing one), a new delta file is created and the corresponding index files must be updated. In MOR, on the other hand, records are written directly to the base file, which means fewer write operations and therefore a lower cost in terms of performance and resource usage.
- Latency: COW has a lower data latency than MOR because new or updated records are first written to a separate delta file, instead of directly updating the base file as in MOR.
- Query times: COW has a shorter query time than MOR because in COW, the updated data is stored in the Delta Files and the original data is kept in the Base File. This means that no read operation is required to get the updated version of the data.
Hudi not only offers different forms of storage, but also different ways of querying the stored information, again depending on both the business cases and the type of storage chosen:
- Snapshots: queries the latest version coming from a commit or compaction. Thanks to this type of queries, it is possible to obtain the versions of the data at specific times thanks to the combination of the base and delta file (time travel). Same performance in CoW and MoR.
- Read Optimized: only available if the type of table in which the data is stored is MoR. Based on obtaining optimized views for reading a large and distributed data set. This is achieved by means of optimized indexing (Bloom Filter Index), which considerably reduces data search time. In addition, it also relies on data compaction, which again makes search tasks less costly by reducing the volume of data.
- Incremental: Allows to read only the data updated or added since the last query. This helps to reduce reading time and disk storage usage.
Conclusions
In this article we have described how to deploy an application that ingests events in real time and forms a LakeHouse with a serverless architecture. With this we have sought an intermediate level of abstraction so that it is a simple application but with enough power to be able to be used in real production environments.
Deploying applications based on the combination of technologies such as Apache Flink and Hudi provides the ability to process large volumes of data in real time and in a scalable manner. This, combined with the guarantee provided by ACID transactions, makes the combination of Apache Flink and Apache Hudi a solid solution for data ingestion and processing in critical environments.
In spite of all the advantages described above, it is worth mentioning some drawbacks that have been detected in the development of this architecture. The biggest problem encountered has been the resolution of dependencies between Flink libraries and the necessary connectors, such as Hudi. The lack of community that exists today, although this will grow over time, was a considerable initial problem to be able to form the final package with all the necessary dependencies without conflicts between them. In addition, it is worth noting that less community has been perceived for the Python language than for Java or Scala. In this article Python was chosen as there was a stronger internal knowledge but in the case that the technology stack is closer to languages supported by the JVM (Java Virtual Machine) it would be advisable to use Scala or Java.
In the next articles we will go into more detail on the particularities that both Hudi and Flink have in order to customize and adjust the behavior of this application depending on the needs of our use case.
References
[1] Github Flink-Hudi (Terraform) repository. [link]
[2] Greenlet 2.0.2. Documentation [link] (February 28, 2023)
[3] Amazon Kinesis Data Analytics Costs. [link] (March 23, 2022)
[4] Hudi Optimized Indexing. [link] (September 23, 2021)
[5] Hudi Writing Concurrency. [link] (September 23, 2021)
Autores
Alfonso Jerez
AWS Cloud Engineer
Comencé mi carrera como Data Scientist en distintos sectores (banca, consultoría,…) enfocado en la automatización de procesos y desarrollo de modelos. En los últimos años aposté por Bluetab motivado por el interés en especializarme como Data Engineer y comenzar a trabajar con los principales proveedores Cloud (AWS, GPC y Azure) en clientes como Olympics, específicamente en la optimización del procesamiento y almacenamiento del dato.
Colaborando activamente con el grupo de Práctica Cloud en investigaciones y desarrollo de blogs de tecnologías punteras e innovadoras tales como esta, fomentando así el continuo aprendizaje.
Navegation
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
SOLUCIONES, SOMOS EXPERTOS
DATA STRATEGY
DATA FABRIC
AUGMENTED ANALYTICS