CDKTF: Otro paso en el viaje del DevOps, introducción y beneficios.

Lucas Calvo
Cloud Engineer

Introducción
En este artículo vamos a hablar de CDKTF y de cómo utilizar todas sus ventajas para desplegar infraestructura de forma programática y reutilizable en GCP. También veremos cómo integrar CDKTF con tus módulos de terraform[1] para desplegar infraestructura más reutilizable bajo la supervisión de tu organización.
CDKTF abre un mundo de posibilidades para llevar a nuestra organización al siguiente nivel de automatización, además de facilitar el despliegue de la infraestructura a las personas más cercanas a la parte de desarrollo. En este artículo daremos algunas indicaciones de cuando es una buena opción utilizar CDKTF y cuando seguir utilizando terraform a través de HCL, ya que no en todos los casos de usos el CDKTF nos aportará un valor añadido.
¿Qué necesitas para entender este artículo?
- Algunos conceptos sobre Terraform[2].
- Instalar el CDKTF [3].
- Algunos conceptos sobre python.
- Necesitas una cuenta gratuita en GCP.
Todo el código utilizado en este artículo está en el repositorio[4] de Github.
¿Es CDKTF la solución milagrosa para los despliegues en nuestra organización? Veámoslo.
¿Que es el CDKTF?
CDKTF, también llamado Cloud Development Kit for Terraform, permite definir y aprovisionar infraestructura de forma programática. En este artículo utilizaremos python para desplegar algunos recursos en GCP. El punto fuerte de CDKTF es que no necesitas aprender HashiCorp Configuration Language (HCL), sólo necesitas saber Python que es más flexible que HCL porque te permite crear más integraciones con herramientas de tu organización y con otras APIs. Incluso puedes crear algunas clases específicas en Python para hacer tu código más reutilizable.

Primeros pasos con CDKTF
Una vez explicado CDKTF, procederemos a crear nuestro primer proyecto. Para ello desplegaremos un cloud storage y un topic de pubsub en GCP, utilizaremos recursos terraform por simplicidad. Comenzaremos explicando varios comandos del CDKTF:
- cdktf init –template=python
Este comando crea un nuevo proyecto CDK para Terraform usando una plantilla. Esto es muy útil cuando se quiere empezar a utilizar un nuevo proveedor, en nuestro caso el proveedor de Google.
Una vez ejecutado este comando veremos la siguiente plantilla:

Los ficheros más importantes son `main.py` y `cdktf.json`. Hablemos de ellos.
En el fichero `main.py` es donde se declara toda la infraestructura que vamos a desplegar con su lógica. Haremos uso del proveedor de Google para definir nuestros recursos, `cloud storage` y `pubsub topic`. Luego para definir e importar el proveedor de google y la librería de almacenamiento y pubsub importaremos los siguientes módulos en python:
```python
from imports.google.provider import GoogleProvider
from imports.google.storage_bucket import StorageBucket
from imports.google.pubsub_topic import PubsubTopic
``` Estos proveedores se definen en el archivo `cdktf.json`, este archivo es donde puedes proporcionar los ajustes de configuración personalizados para tu aplicación y definir los proveedores y módulos que deseas utilizar. Cuando inicializamos la plantilla con el comando `cdktf init –template=python`, la plantilla genera un archivo `cdktf.json` básico en tu directorio raíz que puedes personalizar para tu aplicación.
Este archivo tiene la siguiente información:
```json
{
"language": "python",
"app": "pipenv run python main.py",
"projectId": "da305019-c0fc-4e47-b4ad-1a705cdd8811",
"sendCrashReports": "false",
"terraformProviders": ["google@~> 4.0"],
"terraformModules": [],
"codeMakerOutput": "imports",
"context": {
"excludeStackIdFromLogicalIds": "true",
"allowSepCharsInLogicalIds": "true"
}
}
``` En la línea terraformProviders hemos definido el proveedor de google que contiene todos los recursos que necesitamos. En la sección Integración con tus propios módulos aprenderemos a configurar este fichero para utilizar tus propios módulos terraform.
Una vez configurados los proveedores ya podemos definir nuestros recursos con Python:
```python
class MyStack(TerraformStack):
def __init__(self, scope: Construct, id: str):
super().__init__(scope, id)
GoogleProvider(self, "google", region="europe-west4",project="xxxxx")
length = 5
suffix = ''.join((random.choice(string.ascii_lowercase) for x in range(length)))
bucket = StorageBucket(self, "gcs", name = "cdktf-test-1234-bt-"+ str(suffix), location = "EU", force_destroy = True)
topic = PubsubTopic(self, "topic" ,name = "cdktf-topic", labels={"tool":"cdktf"})
TerraformOutput(self,"bucket_self_link",value=bucket.self_link)
TerraformOutput(self,"topic-id",value=topic.id)
app = App()
MyStack(app, "first_steps")
app.synth()
``` Estas líneas de código despliegan un cloud storage y un topic como hemos dicho previamente, también hemos creado un `string` aleatorio en python para añadir al cloud storage como sufijo. Para ello hemos añadido dos librerías más: `string` y `random`. Además, hemos añadido a nuestro script algunas salidas para ver alguna información importante sobre nuestro despliegue como `topic_id` o `bucket_self_link`.
El resultado final de nuestros primeros scripts con CDKTF es el siguiente:
```python
from constructs import Construct
from cdktf import App, TerraformStack, TerraformOutput
from imports.google.provider import GoogleProvider
from imports.google.storage_bucket import StorageBucket
from imports.google.pubsub_topic import PubsubTopic
import random
import string
class MyStack(TerraformStack):
def __init__(self, scope: Construct, id: str):
super().__init__(scope, id)
GoogleProvider(self, "google", region="europe-west4",project="xxxxx")
length = 5
suffix = ''.join((random.choice(string.ascii_lowercase) for x in range(length)))
bucket = StorageBucket(self, "gcs", name = "cdktf-test-1234-bt-"+ str(suffix), location = "EU", force_destroy = True)
topic = PubsubTopic(self, "topic" ,name = "cdktf-topic", labels={"tool":"cdktf"})
TerraformOutput(self,"bucket_self_link",value=bucket.self_link)
TerraformOutput(self,"topic-id",value=topic.id)
app = App()
MyStack(app, "first_steps")
app.synth()
``` Ahora podemos desplegar nuestra infraestructura, para ello necesitamos ejecutar algunos comandos con CDKTF. En primer lugar, tenemos que descargar los proveedores y módulos para una aplicación y generar las construcciones CDK para ellos. Para ello utilizamos `cdktf get`. Utiliza el archivo de configuración `cdktf.json` para leer la lista de proveedores. Este comando sólo genera los bindings de los proveedores que faltan, por lo que es muy rápido si nada ha cambiado.
```bash
cdktf get
``` Esta es la salida del comando:

Usamos el flag –force para recrear todos los bindings. Con el proveedor descargado procederemos al despliegue ejecutando el comando `cdktf deploy`:
```bash
cdktf deploy
``` Esta es la salida del comando:

Con todos estos pasos hemos procedido a desplegar nuestra primera aplicación con el CDKTF. Algo bastante sencillo y con código muy reutilizable. Ahora vamos a proceder a la destrucción de la infraestructura para no incurrir en ningún coste. Utilizaremos el comando `cdktf destroy`.
Integraciones con tus propios módulos
Perfecto, una vez comprobado cómo funciona el CDKTF vamos a integrarlo con los módulos terraform que se desarrollan en nuestra empresa. Esto nos permitiría hacer el código mucho más reutilizable permitiendo que todo lo que se despliegue en el CDKTF se despliegue con los patrones que hemos definido en los módulos. Para esta prueba ejecutaremos la misma creación (gcs y topic) pero esta vez haciendo uso de los módulos previamente desarrollados que podéis encontrar en el siguiente repositorio.
Estos módulos han sido desarrollados con HCL y tienen ciertas nomenclaturas y lógica para facilitar al máximo el despliegue al resto de desarrolladores de mi organización.
Así que procedamos a crear otra plantilla con el comando `cdktf init –template=python` pero esta vez para usar nuestros propios módulos.
Una vez ejecutado tenemos la misma plantilla que en el apartado anterior. Ahora vamos a proceder a modificar el `cdktf.json` para añadir los módulos que vamos a utilizar y dos proveedores, google y google-beta, que son necesarios para el uso de estos módulos.
Este es el fichero `cdktf.json`:
```json
{
"language": "python",
"app": "pipenv run python main.py",
"projectId": "f02a016f-d673-4390-86db-65348eadfb3f",
"sendCrashReports": "false",
"terraformProviders": ["google@~> 4.0", "google-beta@~> 4.0"],
"terraformModules": [
{
"name": "gcp_pubsub",
"source": "git::https://github.com/lucasberlang/gcp-pubsub.git?ref=v1.2.0"
},
{
"name": "gcp_cloud_storage",
"source": "git::https://github.com/lucasberlang/gcp-cloud-storage.git?ref=v1.2.0"
}
],
"codeMakerOutput": "imports",
"context": {
"excludeStackIdFromLogicalIds": "true",
"allowSepCharsInLogicalIds": "true"
}
}
```
Hemos añadido la línea terraform Modules donde indicamos el nombre del módulo y la fuente, en este caso nuestro repositorio de github. También hemos añadido la línea terraform providers como en el apartado anterior.
Una vez añadidos los proveedores y los módulos terraform vamos a instanciarlos en nuestro main, para ello solo tenemos que añadirlos como librerías y luego invocarlos con los parámetros que estén definidos en nuestro módulo. Puedes ir al readme del módulo que está subido en github para ver que parámetros son obligatorios y cuales son opcionales, también puedes ver salidas de esos módulos.
El código quedaría de la siguiente manera:
```python
#!/usr/bin/env python
from constructs import Construct
from cdktf import App, TerraformStack, TerraformOutput
from imports.google.provider import GoogleProvider
from imports.google_beta.provider import GoogleBetaProvider
from imports.gcp_pubsub import GcpPubsub
from imports.gcp_cloud_storage import GcpCloudStorage
import random
import string
class MyStack(TerraformStack):
def __init__(self, scope: Construct, ns: str):
super().__init__(scope, ns)
GoogleProvider(self, "google", region="europe-west4")
GoogleBetaProvider(self, "google-beta", region="europe-west4")
length = 5
suffix = ''.join((random.choice(string.ascii_lowercase) for x in range(length)))
tags = {"provider" : "go",
"region" : "euw4",
"enterprise" : "bt",
"account" : "poc",
"system" : "ts",
"environment" : "poc",
"cmdb_name" : "",
"security_exposure_level" : "mz",
"status" : "",
"on_service" : "yes"}
topic = GcpPubsub(self,"topic",
name = "cdktf-topic",
project_id = "xxxxxxx",
offset = 1,
tags = tags)
bucket = GcpCloudStorage(self,"bucket",
name = "cdktf-test-1234-bt-" + suffix,
project_id = "xxxxxxx",
offset = 1,
location = "europe-west4",
force_destroy = True,
tags = tags)
TerraformOutput(self,"topic_id",value=topic.id_output)
TerraformOutput(self,"bucket_self_link",value=bucket.bucket_output)
app = App()
MyStack(app, "cdktf_modules")
app.synth()
```
Para invocar nuestros módulos que hemos añadido previamente en el archivo `cdktf.json`, sólo tenemos que añadir este código:
```python
from imports.gcp_pubsub import GcpPubsub
from imports.gcp_cloud_storage import GcpCloudStorage
``` El resto del código es la invocación de nuestros módulos con una serie de parámetros para inicializarlos, como región, nombre, etc. También hemos añadido las salidas para tener algo de información sobre la creación de los recursos en GCP. Ahora, vamos a proceder al despliegue de los recursos para comprobar el correcto funcionamiento de CDKTF.
```bash
cdktf get --force
cdktf deploy
``` Una vez desplegada, comprobaremos nuestra infraestructura en GCP y procederemos a borrar toda con el comando `cdktf destroy`.
Evoluciones que puedes añadir a tu empresa
Gracias al CDKTF podemos crear nuevos automatismos mucho más nativos que con el HCL tradicional ya que podemos integrarnos con todo tipo de backend en nuestro propio desarrollo. Esto abre todo un nuevo mundo de posibilidades en el despliegue automático de infraestructuras.
Por ejemplo, si en tu empresa siempre te piden el mismo tipo de infraestructura desde los equipos de desarrollo, como una base de datos, un cluster kubernetes y luego los componentes de seguridad y comunicaciones asociados al caso de uso, ¿por qué no automatizar este proceso y no crear proyectos terraform a la carta?.
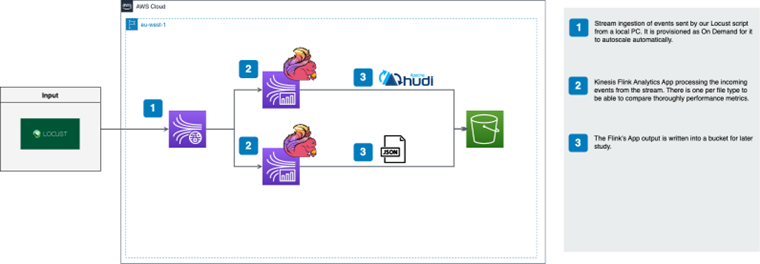
Podemos evolucionar nuestra plataforma de automatización creando un portal web que invoque a nuestro microservicio hecho con el CDKTF que hará las validaciones oportunas y luego procederá al despliegue. Esto también se podría hacer con terraform pero no de una forma tan nativa como con el CDKTF ya que ahora usando python (u otro lenguaje, Typescript, Go etc…) podemos crear flujos de trabajo mucho más complejos llamando a otros backends y haciendo todo tipo de integraciones con nuestras herramientas corporativas. Podríamos generar una plataforma de despliegue para automatizar todos nuestros despliegues genéricos que nos solicitan desde otros equipos como aplicaciones, analítica de datos, reporting, etc. Podríamos crear la siguiente arquitectura para resolver este problema:

Conclusiones
Después de haber trabajado varios años con terraform creo que el CDKTF es su evolución natural, aunque todavía está en una fase prematura. No cuenta con una comunidad tan grande como la que terraform tiene con HCL, lo que hace difícil iniciarse con esta herramienta. Depurar el código suele ser complicado y no tan fácil como con HCL. Los tutoriales oficiales no son muy completos por lo que muchas veces tendrás que encontrar tu propio camino para resolver algunos problemas derivados del uso de CDKTF. También creo que el CDKTF está en un punto de madurez como lo estaba terraform hace años en la versión inferior a la 0.11.0, es decir, funciona bien aunque todavía le queda mucho camino por recorrer.
Creo que si tu empresa ya utiliza terraform (HCL) de forma madura, cambiar el modelo a CDKTF no va a suponer grandes beneficios. El único beneficio de usar CDKTF es en un caso de uso como el mencionado en la sección anterior, donde puedes mezclar el uso de tus módulos ya desarrollados con HCL y CDKTF para llevar la automatización de cierta infraestructura a un nivel superior.
Por otro lado, CDKTF es una herramienta que podría recomendar si conoces python (u otros lenguajes) y no quieres aprender un lenguaje específico como HCL. CDKTF puede ser una buena herramienta si tu empresa no está en un punto de madurez avanzado con terraform o cualquier herramienta de IaC. El CDKTF te permite desarrollar de una forma más sencilla tu infraestructura como código, las integraciones con otras herramientas dentro de tu organización serán mucho más sencillas ya que podrás utilizar tu lenguaje de programación favorito para realizarlas. Puede crear clases y módulos reutilizables de forma sencilla, creando una comunidad de desarrollo CDKTF dentro de su propia empresa y permitiendo a los desarrolladores estar más apegados a la infraestructura, lo que siempre es un reto. También la parte de pruebas de tu código CDKTF será mucho más fácil y nativa haciendo uso de pytest u otros frameworks [7]. Probar con terraform (HCL) es más tedioso y ya tienes que usar frameworks como terratest para integrarlos en tu código.
En general creo que CDKTF es una buena herramienta y es la evolución natural de Terraform. Si queremos llevar nuestra automatización a otro nivel e integrarla con portales web o herramientas organizativas, CDKTF es la herramienta que necesitamos. También abre un mundo de posibilidades para los equipos de desarrollo, ya que podrán desplegar cualquier tipo de infraestructura utilizando un lenguaje de programación. Habrá que ver cómo evoluciona para ver cómo encaja en nuestras organizaciones y si alcanza el punto de madurez que ha alcanzado Terraform.
Referencias
Navegación
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar