{kind=link}


Cloud DevOps Engineer

Desde la Práctica Cloud queremos impulsar el uso de los productos Hashicorp y por ello vamos a publicar artículos temáticos sobre cada uno de ellos.
Debido a la multitud de posibilidades que ofrecen sus productos, en éste artículo abordaremos una visión de conjunto y en publicaciones posteriores, entraremos en detalle de cada uno de ellos, aportando casos de uso no convencionales que muestren el potencial que tienen los productos de Hashicorp.
Durante estos últimos años, Hashicorp viene desarrollando diferentes productos Open Source los cuales ofrecen una gestión transversal de la infraestructura en entornos Cloud y on-premises. Estos productos, han marcado estándares en la automatización de infraestructura.
En la actualidad, sus productos aportan soluciones robustas en los ámbitos del aprovisionamiento, seguridad, interconexión y coordinación de cargas de trabajo.
El código fuente de sus productos está liberado bajo licencia MIT, lo cual ha tenido una gran acogida dentro de la comunidad Open Source (cuentan con más de 100 desarrolladores aportando mejoras de forma continua)
Además de los productos que expondremos en este artículo, disponen de interesantes soluciones Enterprise.
Respecto al impacto que tienen sus soluciones, poniendo como ejemplo Terraform, se ha convertido en un referente en el mercado. Esto significa que Hashicorp está haciendo las cosas bien, por lo que es conveniente entender y aprender a usar sus soluciones.
Aunque nos estemos centrando en su uso en el ámbito Cloud, sus soluciones tiene gran presencia en los entornos on-premises, pero alcanzan todo su potencial cuando trabajamos en la nube.
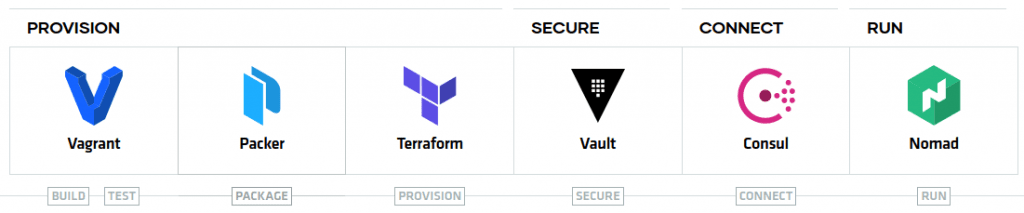
Hashicorp cuenta con los siguientes productos:
A continuación, resumimos las principales características de los productos. En próximas publicaciones entraremos en detalle de cada uno de ellos.

Terraform se ha posicionado como el producto más extendido en el ámbito del aprovisionamiento de Infraestructura como Código.
Utiliza un lenguaje específico (HCL) para desplegar infraestructura a través del uso de los diferentes proveedores de Cloud. Terraform también permite gestionar recursos de otras tecnologías o servicios, como Gitlab o Kubernetes.

Terraform hace uso de un lenguaje declarativo y se basa en tener desplegado exactamente lo que pone en el código.
El típico ejemplo que se muestra para entender la diferencia con el paradigma que sigue por ejemplo Ansible (procedimental) es:
En un primer momento queremos desplegar 5 instancias EC2 en AWS:
- ec2:
count: 5
image: ami-id
instance_type: t2.micro resource "aws_instance" "ejemplo" {
count = 5
ami = "ami-id"
instance_type = "t2.micro"
} Como puede observarse, no existen prácticamente diferencias entre los códigos. Ahora necesitamos desplegar dos instancias más para hacer frente a una carga de trabajo mayor:
- ec2:
count: 2
image: ami-id
instance_type: t2.micro resource "aws_instance" "ejemplo" {
count = 7
ami = "ami-id"
instance_type = "t2.micro"
} En este momento, podemos ver que mientras en Ansible estableceríamos en 2 el número de instancias a desplegar para que en total haya 7 desplegadas, en Terraform estableceríamos el número directamente a 7 y Terraform sabe que tiene que desplegar 2 más porque ya hay 5 desplegadas.
Otro aspecto importante es que Terraform no necesita un server Master como Chef o Puppet. Es una herramienta distribuida cuyo elemento común y centralizado es el tfstate (se explica en el siguiente párrafo). Se lanza desde cualquier sitio con acceso al tfstate (que puede ser remoto, guardado en un almacenamiento común como puede ser AWS S3) y terraform instalado, el cual se distribuye como un binario descargable desde la web de Hashicorp.
El último punto a comentar sobre Terraform es que se basa en un archivo denominado tfstate en el que va guardando y actualizando la información relativa al estado de la infraestructura, y el cual va a consultar para conocer si es necesario realizar cambios sobre la misma. Es muy importante tener en cuenta que este estado es lo que conoce Terraform. Terraform no va a conectarse a AWS para ver qué hay desplegado. Por ello es necesario no realizar cambios a mano sobre infraestructura desplegada por Terraform (ni nunca. Cambios a mano, nunca), ya que no se actualiza el tfstate y por tanto se crearán inconsistencias.

Vagrant permite desplegar entornos de test de manera local de forma rápida y muy simple, basados en código. Por defecto utiliza por debajo VirtualBox, pero es compatible con otros providers como por ejemplo VMWare o Hyper-V. Es posible desplegar máquinas sobre proveedores Cloud como AWS instalando plugins. Personalmente no encuentro la ventaja de usar Vagrant para esta función.
Las máquinas que despliega se basan en boxes, y desde el código se indica qué box se quiere desplegar. En este aspecto podría compararse en modo de funcionamiento con Docker. Sin embargo, la base es totalmente distinta. Vagrant levanta máquinas virtuales con una herramienta de virtualización por debajo (VirtualBox) mientras que Docker despliega contenedores y su soporte es una tecnología de contenerización Vagrant VS Docker.
Casos de uso típicos pueden ser probar playbooks de Ansible, recrear un entorno de laboratorio de manera local en muy pocos minutos, realizar alguna demo, etc.
Vagrant se basa en un archivo Vagrantfile. Una vez situado en el directorio donde se encuentra este Vagrantfile, con ejecutar vagrant up, la herramienta comienza a desplegar lo que se indique dentro de dicho archivo.
Los pasos para lanzar una máquina virtual con Vagrant son:
1- Instalar Vagrant. Se distribuye como un binario al igual que el resto de productos de Hashicorp.
2- Con un Vagrantfile de ejemplo:
Vagrant.configure("2") do |config|
config.vm.box = "gbailey/amzn2"
end PD: (el parámetro 2 dentro de configure se refiere a la versión de Vagrant, que me ha tocado mirarlo para el post)
3- Ejecutar dentro del directorio donde se encuentra el Vagrantfile
vagrant up 4- Entrar por ssh a la máquina
vagrant ssh 5- Destruir la máquina
vagrant destroy Vagrant se encarga de gestionar el acceso ssh creando una clave privada y almacenándola en el directorio .vagrant, aparte de otros metadatos. Se puede acceder a la máquina ejecutando vagrant ssh. También es posible visualizar las máquinas desplegadas en la aplicación de VirtualBox.

Con Packer puedes construir imágenes de máquinas de forma automatizada. Puede utilizarse para, por ejemplo, construir una imagen en un proveedor Cloud como AWS con una configuración inicial ya realizada y poder desplegarla un número indeterminado de veces. De esta forma solo es necesario aprovisionar una sola vez y al desplegar la instancia con esa imagen ya tendrá la configuración deseada sin tener que invertir mayor tiempo en aprovisionarla.
Un pequeño ejemplo sería:
1- Instalar Packer. De la misma forma, es un binario que habrá que colocar en una carpeta que se encuentre en nuestro path.
2- Crear un archivo, por ejemplo builder.json. También se crea un pequeño script en bash (el link que se muestra en builder.json es dummy):
{
"variables": {
"aws_access_key": "{{env `AWS_ACCESS_KEY_ID`}}",
"aws_secret_key": "{{env `AWS_SECRET_ACCESS_KEY`}}",
"region": "eu-west-1"
},
"builders": [
{
"access_key": "{{user `aws_access_key`}}",
"ami_name": "my-custom-ami-{{timestamp}}",
"instance_type": "t2.micro",
"region": "{{user `region`}}",
"secret_key": "{{user `aws_secret_key`}}",
"source_ami_filter": {
"filters": {
"virtualization-type": "hvm",
"name": "amzn2-ami-hvm-2*",
"root-device-type": "ebs"
},
"owners": ["amazon"],
"most_recent": true
},
"ssh_username": "ec2-user",
"type": "amazon-ebs"
}
],
"provisioners": [
{
"type": "shell",
"inline": [
"curl -sL https://raw.githubusercontent.com/example/master/userdata/ec2-userdata.sh | sudo bash -xe"
]
}
]
} Los proveedores utilizan software integrado y de terceros para instalar y configurar la imagen de la máquina después del arranque. Nuestro ejemplo ec2-userdata.sh
yum install -y \
python3 \
python3-pip \
pip3 install cowsay 3- Ejecutar:
packer build builder.json Y ya tendríamos una AMI aprovisionada con cowsay instalado. Ahora nunca más será necesario que, como primer paso tras lanzar una instancia, sea necesario instalar cowsay porque ya lo tendremos de base, como debe ser.
Como es de esperar, Packer no solo funciona con AWS sino con cualquier proveedor Cloud como Azure o GCP. También funciona con VirtualBox y VMWare y una gran lista de builders. Además, se puede crear una imagen anidando builders en el archivo de configuración de Packer que sea igual para distintos proveedores _Cloud. Esto es muy interesante para entornos multi-cloud en los que haya que replicar diferentes configuraciones.

Nomad es un orquestador de cargas de trabajo. A través de sus Task Drivers ejecutan una tarea en un entorno aislado. El caso de uso más común es orquestar contenedores Docker. Tiene dos actores básicos: Nomad Server y Nomad Client. Ambos actores se ejecutan con el mismo binario pero diferente configuración. Los Servers organizan el cluster mientras que los Agents ejecutan las tareas.

Un pequeño “Hello-world” en nomad podría ser:
1- Descargar e instalar Nomad y ejecutarlo (en modo development, este modo nunca debe usarse en producción):
nomad agent -dev Una vez hecho esto ya es posible acceder a la UI de nomad en localhost:4646
2- Ejecutar un job de ejemplo que lanzará una imagen de grafana
nomad job run grafana.nomad grafana.nomad:
job "grafana" {
datacenters = [
"dc1"
]
group "grafana" {
task "grafana"{
driver = "docker"
config {
image = "grafana/grafana"
}
resources {
cpu = 500
memory = 256
network {
mbits = 10
port "http" {
static = "3000"
}
}
}
}
}
} 3- Acceder a localhost:3000 para comprobar que se puede acceder a grafana y acceder a la UI de Nomad (localhost:4646) para ver el job
4- Destruir el job
nomad stop grafana 5- Parar el agente de Nomad. Si se ha ejecutado tal y como se ha indicado aquí, con pulsar Control-C en la terminal donde se está ejecutando bastará
En resumen, Nomad es un orquestador muy ligero, al contrario que Kubernetes. Lógicamente no tiene las mismas funcionalidades que Kubernetes pero ofrece la posibilidad de ejecutar cargas de trabajo en alta disponibilidad de forma sencilla y sin necesidad de usar gran cantidad de recursos. Se tratarán ejemplos con más detalle en el post de Nomad que se publicará en un futuro.

Vault se encarga de gestionar secretos. A través de su api los usuarios o aplicaciones pueden pedir secretos o identidades. Estos usuarios se autentican en Vault, el cual tiene conexión a un proveedor de identidad de confianza como un Active Directory, por ejemplo. Vault funciona con dos tipos de actores al igual que otras de las herramientas mencionadas, Server y Agent.

Al inicializar Vault, comienza en estado sellado (Seal) y se generan diferentes tokens para deshacer el sellado (Unseal). Un caso de uso real sería demasiado largo para este artículo y se verá en detalle en el artículo destinado únicamente a Vault. Sin embargo, se puede descargar y probar en modo dev al igual que se ha mecionado antes con Nomad. En este modo, Vault se inicializa en modo Unsealed , almacenando todo en memoria sin necesidad de autenticación, sin utilizar TLS y con una única clave de sellado. De esta forma podremos jugar con sus funcionalidades y explorarlo de una manera rápida y sencilla.
Consultar en este enlace para mayor información.
1- Instalar Vault. Al igual que el resto de productos de Hashicorp, se distribuye como un binario a través de su web. Una vez hecho, lanzar (este modo nunca debe usarse en producción):
vault server -dev 2- Vault mostrará el token de root que sirve para autenticarse contra Vault. También mostrará la única clave de sellado que crea. Ahora Vault es accesible a través de localhost:8200
3- En otra terminal, exportar las siguientes variables para poder hacer pruebas:
export VAULT_ADDR='http://127.0.0.1:8200'
export VAULT_DEV_ROOT_TOKEN_ID="token-showed-when-running-vault-dev" 4- Crear un secreto (En la terminal en la que se han exportado las variables anteriores)
vault kv put secret/test supersecreto=iewdubwef293bd8dn0as90jdasd 5- Recuperar ese secreto
vault kv get secret/test Estos pasos son el Hello World de Vault, para comprobar su funcionamiento. En el artículo de Vault veremos de forma detallada el funcionamiento y la instalación de Vault, así como más características como las policies, explorar la UI, etc.

Consul sirve para crear una red de servicios. Funciona de forma distribuida y un cliente de consul se ejecutará en una localización en la que existan servicios que se quieran registrar. Consul incluye Health Checking de servicios, una base de datos de clave valor y funcionalidades para securizar el tráfico de red. Al igual que Nomad o Vault, Consul tiene dos actores principales, Server y Agent.

De la misma manera que hemos hecho con Nomad y Vault, vamos a ejecutar Consul en modo dev para mostrar un pequeño ejemplo definiendo un servicio:
1- Instalar Consul. Crear una carpeta de trabajo y dentro de la misma crear un archivo json con un servicio a definir (ejemplo de nombre de carpeta: consul.d).
Archivo web.json (ejemplo de la web de Hashicorp):
{
"service": {
"name": "web",
"tags": [
"rails"
],
"port": 80
}
} 2- Ejecutar el agente de Consul indicándole el directorio de configuración creado antes donde se encuentra web.json (este modo nunca debe usarse en producción):
consul agent -dev -enable-script-checks -config-dir=./consul.d 3- A partir de ahora, aunque no hay nada realmente ejecutándose en el puerto indicado (80), se ha creado un servicio con un nombre DNS al que se puede preguntar para poder acceder al mismo a través de dicho nombre DNS. Su nombre será NAME.service.consul. En nuestro caso NAME es web. Ejecutar para preguntar:
dig @127.0.0.1 -p 8600 web.service.consul Nota: Consul por defecto se ejecuta en el puerto 8600.
De la misma manera se puede preguntar por un record de tipo SRV:
dig @127.0.0.1 -p 8600 web.service.consul SRV También se puede preguntar a través de los tags del servicio (TAG.NAME.service.consul):
dig @127.0.0.1 -p 8600 rails.web.service.consul Y se puede consultar a través de la API:
curl http://localhost:8500/v1/catalog/service/web Nota final: Consul se utiliza como complemento a otros productos, ya que sirve para crear servicios sobre otras herramientas ya desplegadas. Es por ello que este ejemplo no es demasiado ilustrativo. Aparte del artículo específico de Consul, se encontrará como ejemplo en otros artículos como en el de Nomad.
En futuros artículos se explicará también Consul Service Mesh para interconexión de servicios a través de sidecars proxies, la federación de Datacenters de Nomad en Consul para realizar despliegues o las intentions, que sirven para definir reglas de con qué servicios puede comunicarse otro servicio.
Todos estos productos tienen un gran potencial en sus respectivos ámbitos y ofrecen una gestión transversal que puede ayudar a evitar el famoso vendor lock-in de los proveedores de Cloud. Pero lo más importante es su interoperabilidad y compatibilidad.
Mi nombre es Jorge de Diego y estoy especializado en entornos Cloud. Trabajo habitualmente con AWS aunque tengo conocimientos sobre GCP y Azure. Entré en Bluetab en septiembre de 2019 y desde entonces trabajo de Cloud DevOps y tareas de seguridad. Me interesa todo lo relacionado con la tecnología y en especial, los ámbitos de modelos de seguridad e Infraestructura. Podréis identificarme en la oficina por los pantalones cortos.
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar




