Bluetab Utilities & Energy

Senior Cloud Solution Architect


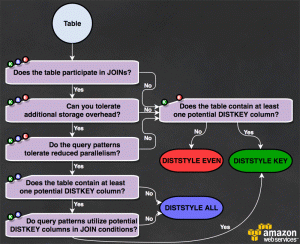
DISTKEY. De esta manera los datos se distribuirán en los diferentes nodos agrupados por los valores de la clave elegida. Esto te permitirá realizar consultas de tipo JOIN sobre esa columna de manera muy eficiente.ALL. Aquellas tablas que son comúnmente usadas en joins de tipo diccionario es recomendable que se copien a todos los nodos. De esta manera la sentencia JOIN realizada con tablas de hechos mucho más grandes se ejecutará mucho más rápido.EVEN. De esta forma los datos se distribuirán de manera aleatoria.SELECT *. e incluye solo las columnas que necesites.WHERE para restringir la cantidad de datos a leer.GROUP BY y SORT BY para que el planificador de consultas pueda usar una agregación más eficiente.






Director Operaciones América


 Actualmente además de los avances en sistemas de predicción meteorológica, los sistemas GPS o la fotografía satelital, los drones son una de las áreas de mayor desarrollo. Estas plataformas proporcionan información detallada sobre situación hidrológica, maduración de la cosecha o situación fitosanitaria. Las cámaras que montan actualmente plataformas Drone como DJI, permiten desde levantar geometrías tridimensionales del terreno, a identificar con precisión de centímetros donde aplicar agua o productos fitosanitarios y hasta el momento más adecuado para la cosecha de cada metro cuadrado. Todo ello mediante servicios disponibles en plataformas en la nube, utilizando algoritmos disponibles capaces de identificar número y tamaños de cosecha, o plagas específicas y su localización.
Actualmente además de los avances en sistemas de predicción meteorológica, los sistemas GPS o la fotografía satelital, los drones son una de las áreas de mayor desarrollo. Estas plataformas proporcionan información detallada sobre situación hidrológica, maduración de la cosecha o situación fitosanitaria. Las cámaras que montan actualmente plataformas Drone como DJI, permiten desde levantar geometrías tridimensionales del terreno, a identificar con precisión de centímetros donde aplicar agua o productos fitosanitarios y hasta el momento más adecuado para la cosecha de cada metro cuadrado. Todo ello mediante servicios disponibles en plataformas en la nube, utilizando algoritmos disponibles capaces de identificar número y tamaños de cosecha, o plagas específicas y su localización.

 Otro elemento fundamental son las plataformas de datos abiertos, desde meteorológicos, satelitales o geológicos a históricos en determinadas geografías. El cruce de estos con los datos propios, permiten desde predecir mejor fenómenos meteorológicos y su impacto en la maduración de la cosecha a predecir el futuro volumen de la misma y su valor en el mercado.
Otro elemento fundamental son las plataformas de datos abiertos, desde meteorológicos, satelitales o geológicos a históricos en determinadas geografías. El cruce de estos con los datos propios, permiten desde predecir mejor fenómenos meteorológicos y su impacto en la maduración de la cosecha a predecir el futuro volumen de la misma y su valor en el mercado.
 Finalmente, un elemento diferencial son los vehículos autónomos de empresas como John Deere que fabrica tractores que utilizan los mismos modelos de inteligencia artificial usados en coches autónomos tan sofisticados como el Waymo de Alphabet. Modelos de reconocimiento de imagen permiten colocar y medir las actuaciones de forma que llegan a reducirse en la aplicación de herbicidas o fertilizantes entre un 70 a un 90%. Hay que tener en cuenta que en condiciones normales aproximadamente un 50% de los fertilizantes se pierden en el ambiente.
Finalmente, un elemento diferencial son los vehículos autónomos de empresas como John Deere que fabrica tractores que utilizan los mismos modelos de inteligencia artificial usados en coches autónomos tan sofisticados como el Waymo de Alphabet. Modelos de reconocimiento de imagen permiten colocar y medir las actuaciones de forma que llegan a reducirse en la aplicación de herbicidas o fertilizantes entre un 70 a un 90%. Hay que tener en cuenta que en condiciones normales aproximadamente un 50% de los fertilizantes se pierden en el ambiente.


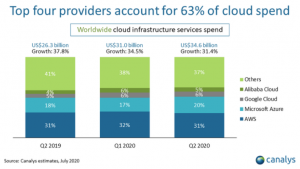 Podemos decir en términos generales, que actualmente la plataforma AWS lleva la delantera a sus competidores en lo que tiene que ver con posición de mercado, si bien ha tenido una pequeña reducción de su posición en el ultimo año. Y esto hace que en mercados como España o México nuestra percepción es que el número de recursos disponibles es tambien mayor.
Podemos decir en términos generales, que actualmente la plataforma AWS lleva la delantera a sus competidores en lo que tiene que ver con posición de mercado, si bien ha tenido una pequeña reducción de su posición en el ultimo año. Y esto hace que en mercados como España o México nuestra percepción es que el número de recursos disponibles es tambien mayor.