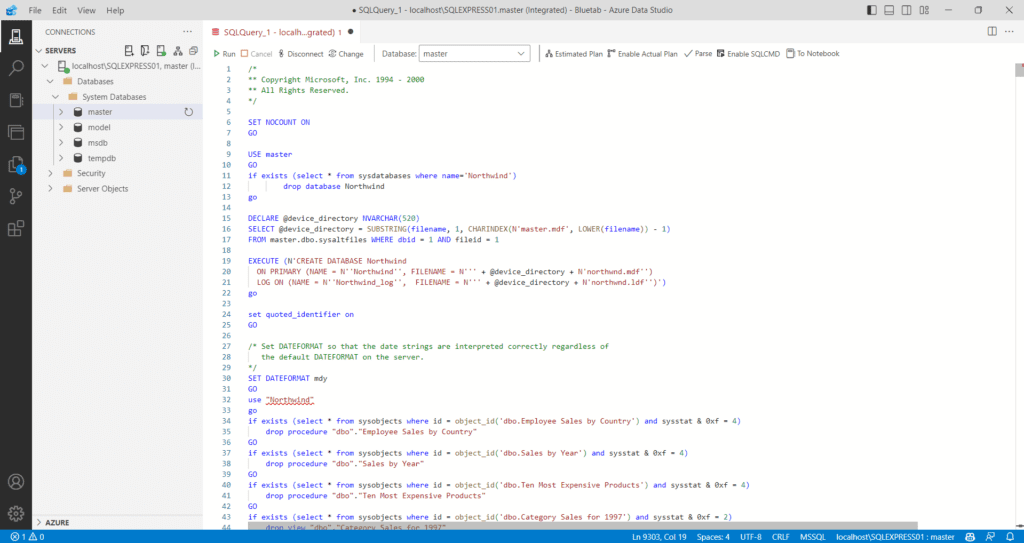
PERSONAL MAPS: conociéndonos más

Pilar Chavarri
Delivery Manager

En Bluetab, tenemos una cultura empresarial que tiene la capacidad de atraer a los más destacados expertos en el ámbito de los datos. El enfoque se centra en la valoración del conocimiento, la experiencia y la ejecución de tareas con excelencia. Sin embargo, por encima de todo, se otorga un valor primordial a la actitud positiva y a la gente que forma parte de nuestra empresa.
Para comprender el valor de «personal maps» como herramienta de gestión aplicada en nuestros proyectos, es importante partir de la siguiente idea general: antes que CONSULTORES somos PERSONAS. Personas con identidad propia, es decir, que vivimos en sociedad y tenemos la sensibilidad sobre nosotros y nuestro entorno, además de contar con inteligencia y voluntad para realizar nuestras funciones en cada ámbito de la vida.
En toda organización o empleo, las personas interactúan diariamente, ya sea de manera física o virtual. Sin embargo, ¿realmente se conoce a profundidad a las personas con las que se trabaja o simplemente se está familiarizado con lo que muestran en su día a día? ¿Por qué resulta necesario este mutuo conocimiento? El valor radica en la construcción de un vínculo de confianza, lo que a su vez conduce a la formación de un equipo más sólido y resistente.
Aproximarse a las labores de los colegas con el propósito de comprender con mayor claridad los acontecimientos de valor para ellos, contribuye a acortar la brecha entre cada individuo, lo que a su vez potencia la comunicación del equipo, la sinergia y la creatividad. A través de este proceso de interrelación que hemos puesto en práctica, se adquiere información sobre los factores que estimulan la ambición de los demás y los elementos que los mantienen motivados.
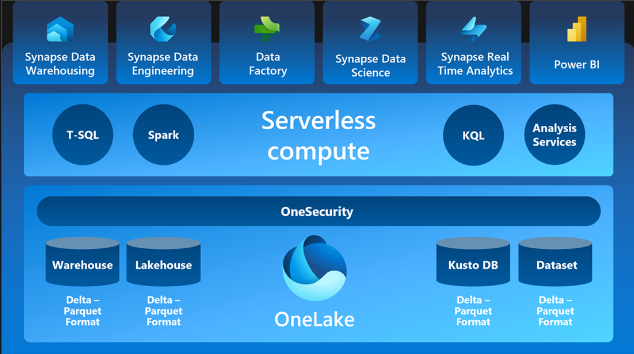
La herramienta “personal maps” es presentada como parte de la corriente conocida como «Manager 3.0». Esta corriente no se configura como otro marco metodológico de gestión, sino más bien como una mentalidad que se fusiona con un conjunto de juegos, herramientas y prácticas en constante evolución, con el propósito de asistir a todo trabajador en la dirección de la organización y sus procedimientos.
La herramienta contribuye a establecer conexiones más estrechas entre los integrantes de un equipo, posibilitando así una mayor comprensión de las personas y promoviendo una colaboración más efectiva (Management 3.0, 2016). La implementación de Personal Maps se inicia al colocar el nombre de la persona en el centro de la representación gráfica. A continuación, se añaden categorías que resultan relevantes alrededor del nombre, tales como familia, educación, trabajo, hobbies, amigos, objetivos y valores. A medida que avanza el proceso, es posible incorporar más aspectos pertinentes acerca de la persona. Personal Maps puede ser confeccionado en soportes físicos como hojas de papel o en herramientas informáticas tales como PowerPoint, Mural, Miro, Prezi, entre otros.
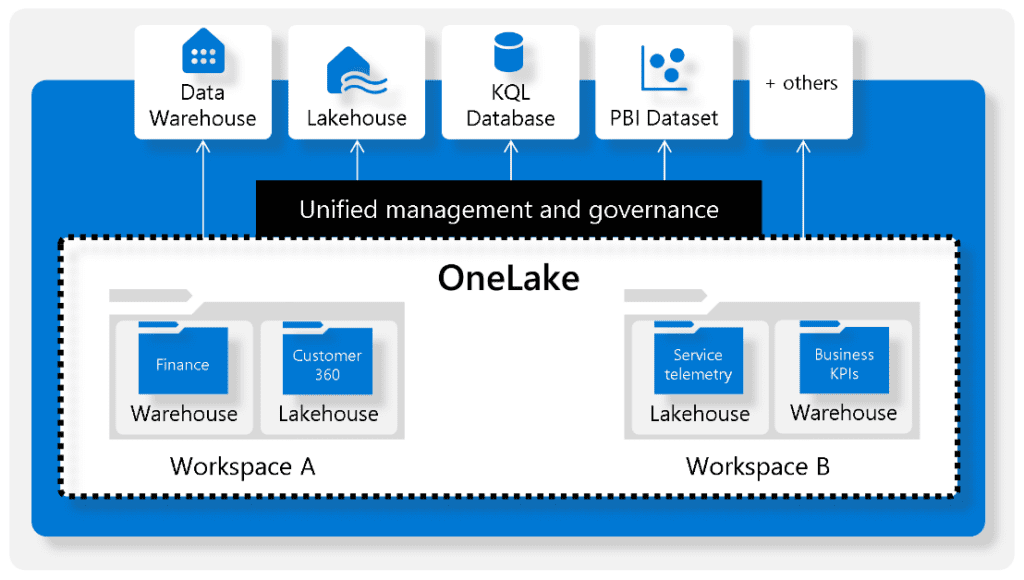
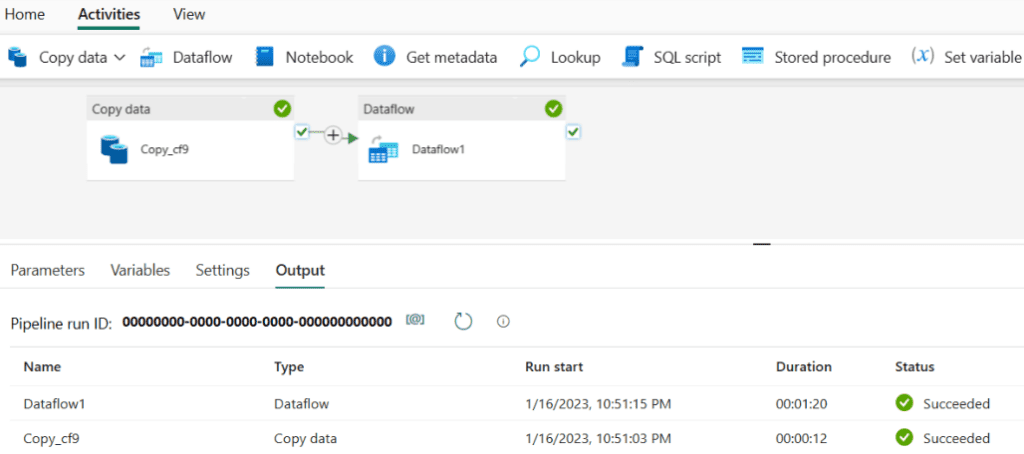
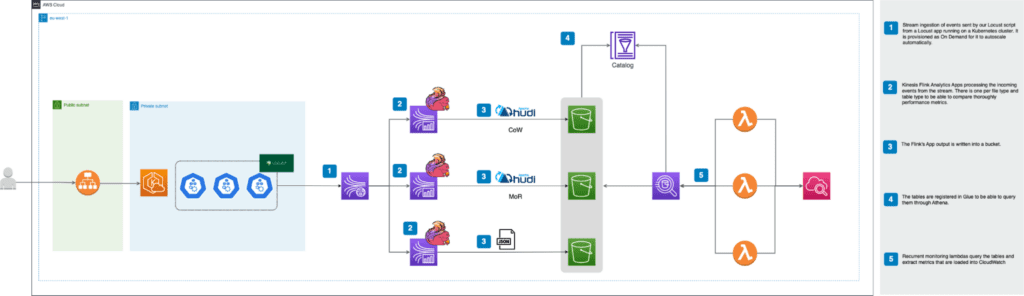
A continuación, se presenta un ejemplo visual de la herramienta:
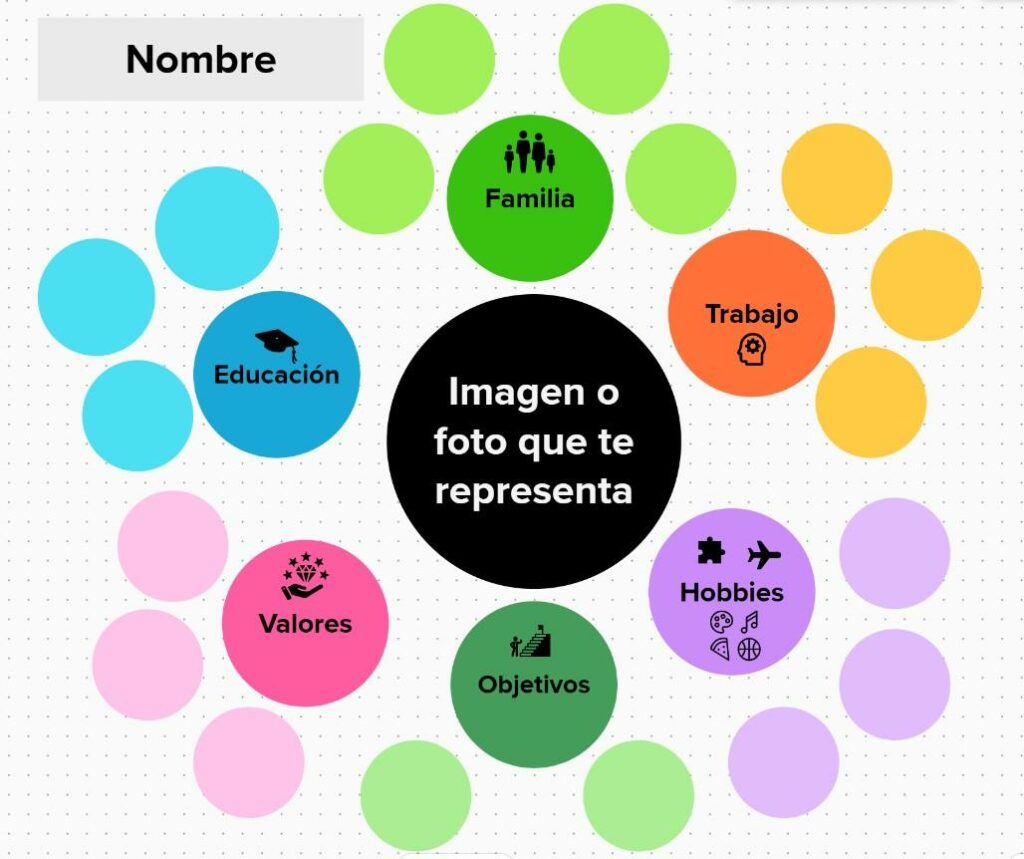
Experiencia de aplicación de Personal Maps
Se dio comienzo a un proyecto de migración de datos en un cliente de Bluetab en el que se involucraron profesionales con el propósito de llevar a cabo su implementación. Estos talentos humano (que no habían laborado juntos previamente) se vieron en la necesidad de conocerse mutuamente para llevar adelante esta iniciativa.
Este proyecto se llevó a cabo de manera remota y se identificó una falta de sinergia dentro del equipo. Para fomentar tanto la comunicación como la confianza entre los miembros del grupo, se optó por implementar la herramienta Personal Maps a través de la plataforma Mural. Esta actividad tuvo lugar en productiva sesión que se denominó como «conociéndonos más «.
El equipo demostró un entusiasmo palpable por profundizar en el conocimiento mutuo. Al iniciar la sesión, se planteó a los integrantes si tenían conciencia de aspectos personales de los demás miembros, lo cual suscitó asombro en muchos casos. Con el propósito de fomentar el vínculo y generar un ambiente de confianza, se compartió información acerca de uno de los miembros y su hijo. Posteriormente, se introdujo la herramienta Personal Maps, presentando una plantilla que debía ser completada, tomando como referencia un mapa personal previamente elaborado.
En el transcurso de la reunión, se llevaron a cabo las siguientes etapas:
- Elaboración del Personal Maps: se propuso la plantilla del Personal Maps con el fin de que cada participante la completara. Además, se facilitó su edición y se brindó la opción de incorporar imágenes.
- Presentación individual mediante Personal Maps: para ejemplificar, el facilitador realizó su propia presentación utilizando Personal Maps. En este caso, se incluyeron fotografías con el objetivo de crear un ambiente propicio para el desarrollo de la confianza.
- Al culminar la edición del Personal Maps, el equipo se presentó detallando y explicando su mapa personal.
- Posteriormente, se dio paso a una ronda de preguntas y consultas por parte del equipo con relación a las presentaciones realizadas.

Resultó ser una sesión sumamente acogedora y, sin lugar a duda, contribuyó de manera significativa a nuestro conocimiento mutuo y a la construcción de un mayor nivel de confianza. Cada individuo optó por abrirse y compartir aspectos íntimos y personales, brindándonos una perspectiva más profunda de su mundo y su persona.
A modo de ejemplo, en el transcurso de esta actividad se obtuvo información valiosa como la siguiente:
- Uno de los colaboradores compartió que padece de daltonismo. Aunque muchos podrían estar familiarizados con esta condición, el testimonio de la persona afectada proporcionó una comprensión mucho más rica y detallada de la enfermedad.
- Otro colaborador reveló su condición de vegano, proporcionando detalles que suscitaron numerosas consultas por parte de los demás compañeros.
- Además, otro colaborador compartió estar en proceso de recibir un trasplante de córnea, dejando a muchos de los presentes asombrados.
Toda esta actividad propició que todos los integrantes del equipo experimentaran una sensación de cercanía, contribuyendo así a una mayor complementación entre ellos. Además, se observó una mejora significativa en la empatía, la colaboración y el trabajo en equipo. A raíz de esta sesión, se percibió cómo todos los miembros del equipo se mostraban dispuestos a brindarse ayuda mutua de manera más activa.
APRENDIZAJES
La aplicación de la herramienta «Personal Maps» en Bluetab ha generado una serie de valiosos aprendizajes que han enriquecido nuestro entorno cultural y por ello la recomendamos:
- Se ha evidenciado la importancia de aplicar Personal Maps al momento de partir con un nuevo proyecto y equipo. Además, la accesibilidad a los mapas es útil para el equipo posterior a la sesión, porque ha demostrado permitir revisiones y reflexiones continuas.
- La implementación de esta herramienta ha generado una conexión más profunda entre los individuos, impulsando la necesidad natural de plantear preguntas que fomenten un entendimiento más completo de las dimensiones personales de los colegas.
- El equipo manifestó su satisfacción por la aplicación de la herramienta.
- Esta herramienta permitió descubrir y comprender las motivaciones, temores y desmotivaciones de los miembros del equipo.
- El “Personal Maps» ha contribuido al desarrollo de un equipo más cohesionado en los proyectos Bluetab. La posibilidad de adentrarse en las personalidades, entornos y vidas de los demás ha fomentado la habilidad de adoptar perspectivas diversas y fortalecer la empatía entre los miembros del equipo.
Estos aprendizajes han enriquecido nuestra cultura empresarial y han impulsado una mayor comprensión y colaboración entre los bluetabers.
Y tú, ¿estás dispuesto a ponerla en práctica y medir sus resultados?
- Se les hace una cordial invitación a utilizar esta herramienta sencilla y valiosa a la vez.
- Para más información, pueden ingresar al siguiente enlace: https://management30.com/practice/personal-maps/
Pilar Chavarri
Delivery Manager
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar