MICROSOFT FABRIC: Una nueva solución de análisis de datos, todo en uno

Deygerson Méndez
Data Engineer

En el dinámico mundo empresarial actual; la tecnología es la clave para la innovación y el éxito. Por ello, si estás buscando una forma fresca y emocionante de potenciar las capacidades de análisis de datos de tu organización, estás en el lugar correcto.
En el siguiente artículo te contaremos desde bluetab, nuestra experiencia sobre Microsoft Fabric, la nueva solución de análisis que nos ofrece este big player tecnológico. Con ella podemos abarcar todo el ciclo de vida del dato, es decir, desde el movimiento de datos pudiendo crear pipelines para la ingesta, hasta la transformación y carga de los mismos. A su vez, el análisis en tiempo real, la inteligencia empresarial, la gobernanza y el cumplimiento, todo ello en un mismo espacio de trabajo; además de contar con herramientas de inteligencia artificial integradas, que nos ayudan a generar soluciones basadas en información en un menor tiempo.
¿Qué es Microsoft Fabric?
La documentación oficial de Microsoft describe el servicio como “no es solo otra solución tecnológica, sino una plataforma integral diseñada para simplificar y optimizar sus procesos empresariales mediante una infraestructura moderna, la cual se presenta, como una solución altamente integrada y fácil de usar”.
Microsoft Fabric está basado, en un modelo de Software como Servicio (SaaS) que lleva la simplicidad y la integración a un siguiente nivel.
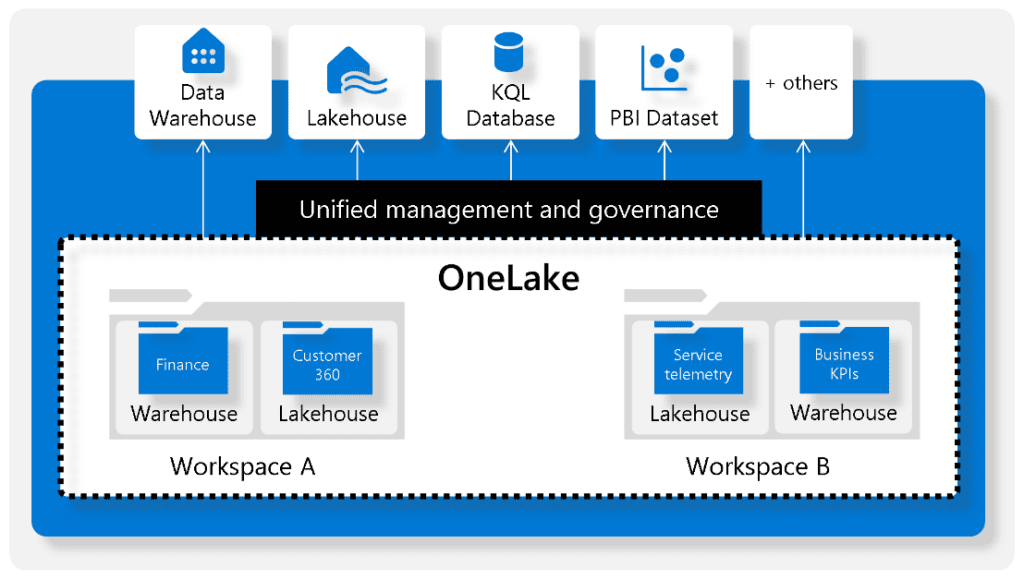
A la vez, ofrece un conjunto completo de servicios, que incluye un lago de datos unificado denominado OneLake, que permite mantener los datos en su lugar mientras utiliza sus herramientas de análisis preferidas, e incorpora servicios nuevos y existentes como Power BI, Azure Synapse Analytics y Azure Data Factory en un entorno unificado.
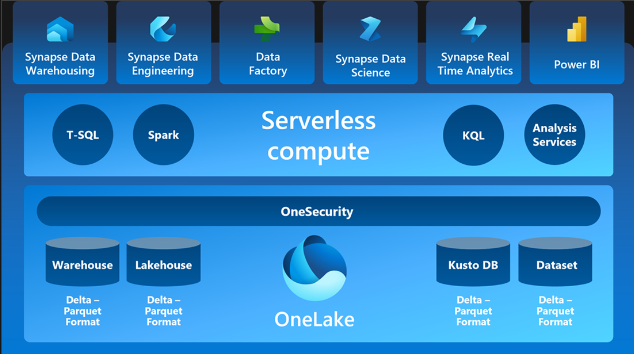
Es importante mencionar que está integración nos ofrece grandes ventajas, como, por ejemplo:
- Amplia gama de capacidades integradas: Esto quiere decir que proporciona una suite completa de capacidades de análisis profundamente integradas, abarcando desde la ingeniería de datos, la ciencia de datos y el análisis en tiempo real.
- Toma decisiones informadas: Gracias a la analítica avanzada de Microsoft Fabric, podrá tomar decisiones basadas en datos sólidos, impulsando así su estrategia empresarial.
- Más eficiencia, menos esfuerzo: Al automatizar procesos repetitivos, Microsoft Fabric le libera para que pueda concentrarse en tareas más importantes y creativas.
- Colaboración sin fronteras: La capacidad de colaborar en tiempo real entre equipos, independientemente de su ubicación, fomenta la creatividad y la innovación.
- Gestión y gobernanza centralizadas: Con una sólida administración, Microsoft Fabric ofrece gobernanza y control en todas las experiencias.
Herramientas especializadas para cada necesidad:
Conviene especificar que, Microsoft Fabric nos ofrece un conjunto completo de experiencias de análisis diseñadas para trabajar conjuntamente sin problemas, cada una de ellas se adapta a un rol y tarea específica:
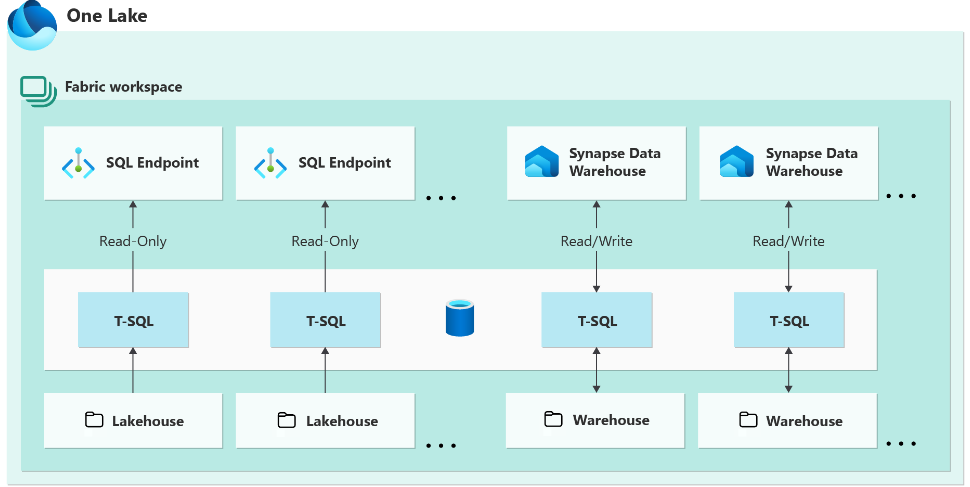
- OneLake: Proporciona una ubicación unificada para almacenar todos los datos de la organización, donde se dan las experiencias.
- Synapse Data Warehousing: Ofrece un rendimiento líder en SQL y separa el proceso de almacenamiento, escalando independientemente cada componente.
Synapse Data Engineering: Proporciona una plataforma Spark de primer nivel, para transformar datos a gran escala y democratizar el uso de los datos.
- Data Factory: Combina la simplicidad de Power Query con la potencia de Azure Data Factory, conectándote a más de 200 orígenes de datos.
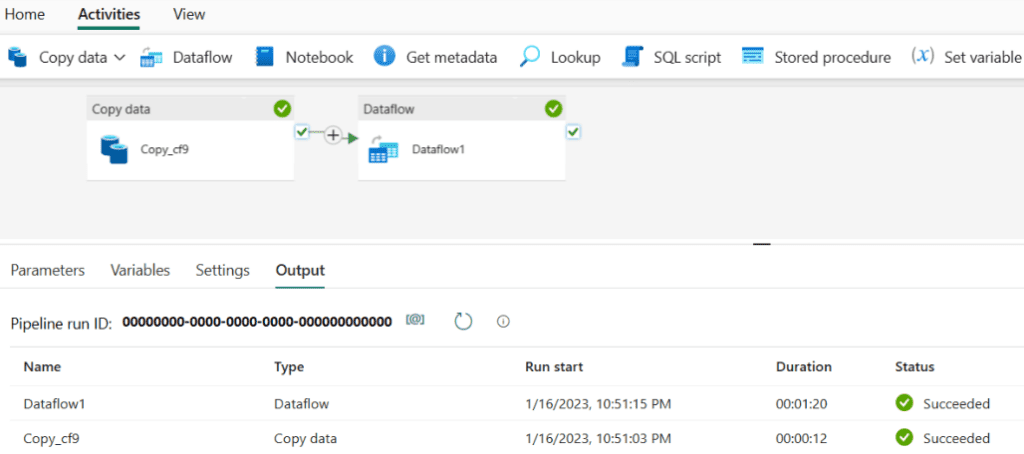
- Synapse Data Science: Permite crear, implementar y desplegar modelos de aprendizaje automático con facilidad, conectándose a Azure Machine Learning.

- Synapse Real-Time Analytics: Puede transmitir grandes volúmenes de datos a la base de datos de KQL, con una latencia de pocos segundos, después usar un conjunto de consultas KQL para analizar y visualizar los resultados en informes de Power BI.
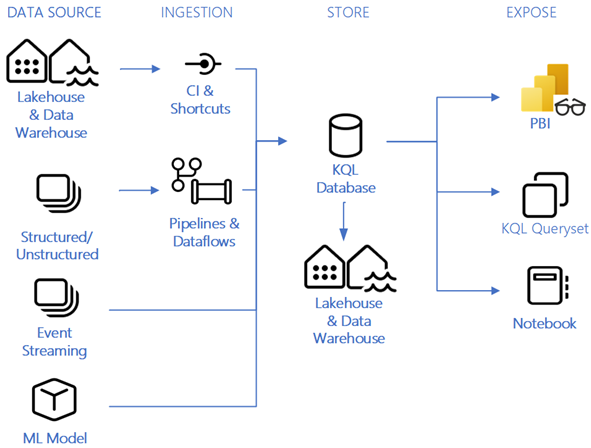
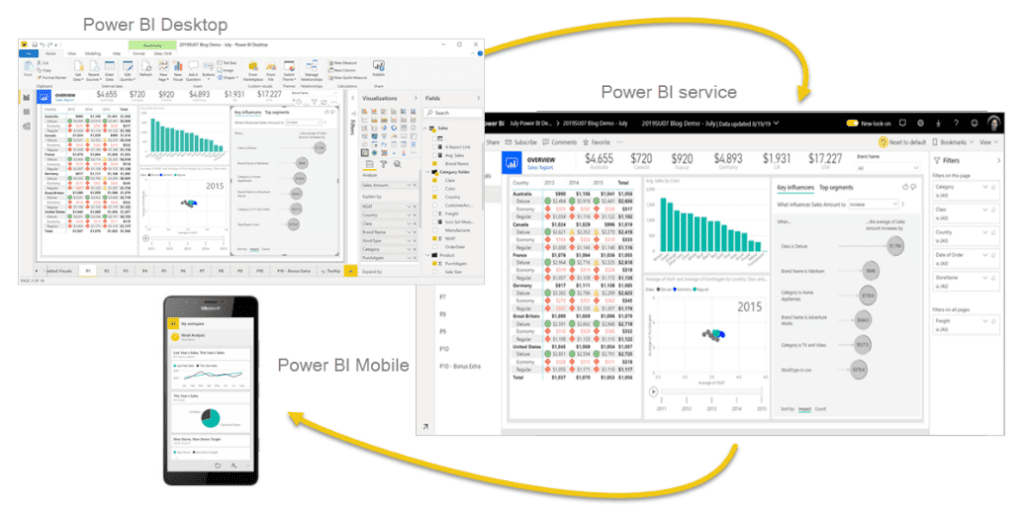
- Power BI: La plataforma líder en inteligencia empresarial que permite tomar decisiones fundamentadas basadas en los datos.
Reducción de costos a través de capacidades unificadas:
En la actualidad, es común que los sistemas analíticos fusionen productos de diversos proveedores en un solo proyecto. Operando de forma independiente, implica una distribución de capacidad de cómputo en múltiples sistemas. Cuando uno de estos sistemas no se encuentra en uso, su potencial queda inhabilitado, lo que genera un notable desperdicio de recursos.
Fabric simplifica de manera significativa, la adquisición y gestión de recursos, ya que tendrás la posibilidad de adquirir un único conjunto de recursos computacionales, que potencian todas las operaciones, generando una reducción sustancial de costos, dado que cualquier unidad de cómputo sin uso puede ser aprovechada por cualquier otra operación.
Impulsado por inteligencia artificial:
Gracias a la integración de Copilot (asistente de programación impulsado por inteligencia artificial desarrollado por GitHub), tendrás la capacidad de utilizar el lenguaje conversacional para desarrollar flujos, pipelines de datos, generar código, idear modelos de aprendizaje automático o visualizar los resultados obtenidos. Incluso podrás crear tus propias experiencias de lenguaje conversacional que combinen los modelos de Azure OpenAI Service.
Para conocer más acerca del servicio podrías ingresar al siguiente enlace:
https://www.microsoft.com/es-es/microsoft-fabric
Entonces, ¿estás preparado para dar el salto?
Aunque Microsoft Fabric se encuentra en su fase de prelanzamiento, ha sido meticulosamente diseñado para desafiar las convenciones y llevar a su empresa a un nivel completamente nuevo.
Puedes suscribirte a la evaluación gratuita del servicio, sin necesidad de suministrar información de una tarjeta de crédito, en el siguiente enlace: https://learn.microsoft.com/es-es/fabric/get-started/fabric-trial
A modo de conclusión, Microsoft Fabric puede agregar valor y a la vez estarás listo para afrontar nuevos retos, crear experiencias excepcionales para tus clientes y alcanzar los objetivos en el análisis empresarial que son demandados por tu organización.
Mediante su uso, los usuarios tendrán la capacidad de emplear un único producto que posee una estructura y experiencia cohesionadas, otorgando todas las competencias esenciales para que los desarrolladores extraigan conocimientos de los datos y los presenten a los interesados comerciales.
Gracias a su enfoque (SaaS), todos los aspectos se fusionan y ajustan de manera automática, habilitando a los usuarios a registrarse rápidamente y empezar a obtener un valor empresarial tangible en cuestión de minutos. En Bluetab América, an IBM Company, nos encontramos entusiasmados por el potencial de esta nueva solución y estamos preparados con el mejor staff de profesionales, para ser un aliado estratégico en la implementación de este emocionante servicio.
Deygerson Méndez
Data Engineer
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar