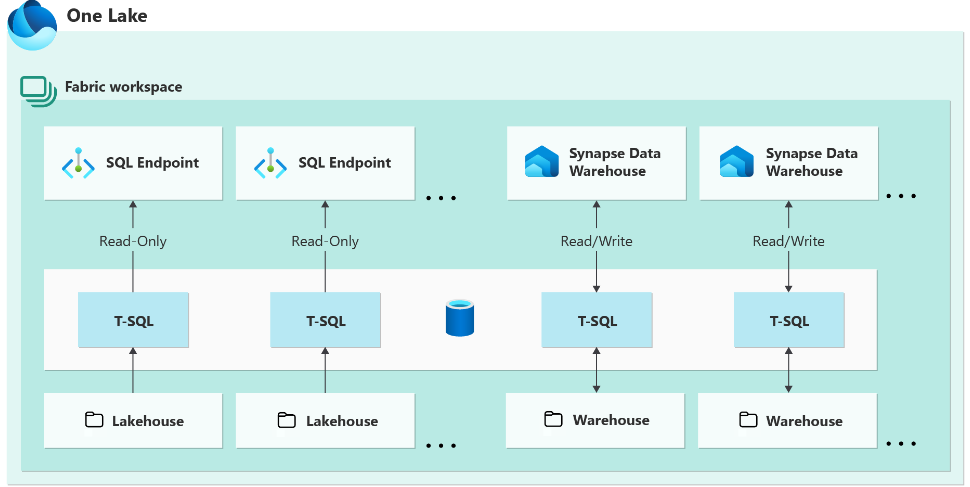
Análisis de vulnerabilidades en contenedores con trivy

Ángel Maroco
AWS Cloud Architect

Dentro del marco de la seguridad en contenedores, la fase de construcción adquiere vital importancia debido a que debemos seleccionar la imagen base sobre la que ejecutarán las aplicaciones. El no disponer de mecanismos automáticos para el análisis de vulnerabilidades puede desembocar en entornos productivos con aplicaciones inseguras con los riesgos que ello conlleva.
En este artículo cubriremos el análisis de vulnerabilidades a través de la solución Trivy de Aqua Security, pero antes de comenzar, es preciso explicar en qué se basan este tipo de soluciones para identificar vulnerabilidades en las imágenes docker.
Introducción a CVE (Common Vulnerabilities and Exposures)
CVE es una lista de información mantenida por MITRE Corporation cuyo objetivo es centralizar el registro de vulnerabilidades de seguridad conocidas, en la que cada referencia tiene un número de identificación CVE-ID, descripción de la vulnerabilidad, que versiones del software están afectadas, posible solución al fallo (si existe) o como configurar para mitigar la vulnerabilidad y referencias a publicaciones o entradas de foros o blog donde se ha hecho pública la vulnerabilidad o se demuestra su explotación.
El CVE-ID ofrece una nomenclatura estándar para identificar de forma inequívoca una vulnerabilidad. Se clasifican en 5 tipologías, las cuales veremos en la sección Interpretación del análisis. Dichas tipologías son asignadas basándose en diferentes métricas (si tenéis curiosidad, consultad CVSS v3 Calculator)
CVE se ha convertido en el estándar para el registro de vulnerabilidades, por lo que la amplia mayoría de empresas de tecnología y particulares hacen uso de la misma.
Disponemos de múltiples canales para estar informados de todas las novedades referentes a vulnerabilidades: blog oficial, twitter, repositorio cvelist en github o LinkedIn.
Adicionalmente, si queréis información más detallada sobre una vulnerabilidad, podéis consultar la web del NIST, en concreto la NVD (National Vulnerability Database)
Os invitamos a buscar alguna de las siguientes vulnerabilidades críticas, es muy posible que de forma directa o indirecta os haya podido afectar. Os adelantamos que han sido de las más sonadas 
- CVE-2017-5753
- CVE-2017-5754
Si detectas una vulnerabilidad, te animamos a registrarla a través del siguiente formulario
Aqua Security – Trivy
Trivy es una herramienta open source enfocada en la detección de vulnerabilidades en paquetes a nivel OS y ficheros de dependencias de distintitos lenguajes:
- OS packages; (Alpine, Red Hat Universal Base Image, Red Hat Enterprise Linux, CentOS, Oracle Linux, Debian, Ubuntu, Amazon Linux, openSUSE Leap, SUSE Enterprise Linux, Photon OS and Distroless)
- Application dependencies: (Bundler, Composer, Pipenv, Poetry, npm, yarn and Cargo)
Aqua Security, empresa especializada en el desarrollo de soluciones de seguridad, adquirió trivy en 2019. Junto a un amplio número de colaboradores, son los encargados del desarrollo y mantenimiento de la misma.
Instalación
Trivy dispone de instaladores para la mayor parte de sistemas Linux and macOS. Para nuestras pruebas vamos a utilizar el instalador genérico:
curl -sfL https://raw.githubusercontent.com/aquasecurity/trivy/master/contrib/install.sh | sudo sh -s -- -b /usr/local/bin Si no queremos persistir el binario en nuestro sistema, disponemos de una imagen docker:
docker run --rm -v /var/run/docker.sock:/var/run/docker.sock -v /tmp/trivycache:/root/.cache/ aquasec/trivy python:3.4-alpine Operaciones básicas
- Imágenes locales
Trivy dispone de instaladores para la mayor parte de sistemas Linux and macOS. Para nuestras pruebas vamos a utilizar el instalador genérico:
#!/bin/bash
docker build -t cloud-practice/alpine:latest -<<EOF
FROM alpine:latest
RUN echo "hello world"
EOF
trivy image cloud-practice/alpine:latest - Imágenes remotas
#!/bin/bash
trivy image python:3.4-alpine - Proyectos locales:
Permite analizar ficheros de dependencias (salidas):- Pipfile.lock: Python
- package-lock_react.json: React
- Gemfile_rails.lock: Rails
- Gemfile.lock: Ruby
- Dockerfile: Docker
- composer_laravel.lock: PHP Lavarel
- Cargo.lock: Rust
#!/bin/bash
git clone https://github.com/knqyf263/trivy-ci-test
trivy fs trivy-ci-test - Repositorios públicos:
#!/bin/bash
trivy repo https://github.com/knqyf263/trivy-ci-test - Repositorios de imágenes privados:
- Cache database
La base de datos de vulnerabilidades se aloja en github. Para evitar descargar dicha base de datos en cada operación de análisis, podemos utilizar el parámetro--cache-dir <dir>:
#!/bin/bash trivy –cache-dir .cache/trivy image python:3.4-alpine3.9 - Filtrar por criticidad
#!/bin/bash
trivy image --severity HIGH,CRITICAL ruby:2.4.0 - Filtrar vulnerabiliades no resueltas
#!/bin/bash
trivy image --ignore-unfixed ruby:2.4.0 - Especificar código de salida
Esta opción en muy util en el proceso de integración continua, ya que podemos especificar que nuestro pipeline finalice con error cuando se encuentre vulnerabilidad de tipo critical pero las tipo medium y high finalicen correctamente.
#!/bin/bash
trivy image --exit-code 0 --severity MEDIUM,HIGH ruby:2.4.0
trivy image --exit-code 1 --severity CRITICAL ruby:2.4.0 - Ignorar vulnerabilidades específicas
A través del fichero .trivyignore, podemos especificar aquellas CVEs que nos interesa descartar. Puede resultar útil si la imagen contiene una vulnerabilidad que no afecta a nuestro desarrollo.
#!/bin/bash
cat .trivyignore
# Accept the risk
CVE-2018-14618
# No impact in our settings
CVE-2019-1543 - Exportar salida en formato JSON:
Esta opción es interesante si quieres automatizar un proceso antes una salida, visualizar los resultados en un front personalizado o persistir la salida con un formato estructurado.
#!/bin/bash
trivy image -f json -o results.json golang:1.12-alpine
cat results.json | jq - Exportar salida en formato SARIF:
Existe un estandar llamado SARIF (Static Analysis Results Interchange Format) que define el formato que deben tener las salidas cualquier herramienta de análisis de vulnerabilidades.
#!/bin/bash
wget https://raw.githubusercontent.com/aquasecurity/trivy/master/contrib/sarif.tpl
trivy image --format template --template "@sarif.tpl" -o report-golang.sarif golang:1.12-alpine
cat report-golang.sarif VS Code dispone de la extensión sarif-viewer para la visualización de vulnerabilidades.
Procesos de integración contínua
Trivy dispone de plantillas para las principales soluciones de CI/CD:
#!/bin/bash
$ cat .gitlab-ci.yml
stages:
- test
trivy:
stage: test
image: docker:stable-git
before_script:
- docker build -t trivy-ci-test:${CI_COMMIT_REF_NAME} .
- export VERSION=$(curl --silent "https://api.github.com/repos/aquasecurity/trivy/releases/latest" | grep '"tag_name":' | sed -E 's/.*"v([^"]+)".*/\1/')
- wget https://github.com/aquasecurity/trivy/releases/download/v${VERSION}/trivy_${VERSION}_Linux-64bit.tar.gz
- tar zxvf trivy_${VERSION}_Linux-64bit.tar.gz
variables:
DOCKER_DRIVER: overlay2
allow_failure: true
services:
- docker:stable-dind
script:
- ./trivy --exit-code 0 --severity HIGH --no-progress --auto-refresh trivy-ci-test:${CI_COMMIT_REF_NAME}
- ./trivy --exit-code 1 --severity CRITICAL --no-progress --auto-refresh trivy-ci-test:${CI_COMMIT_REF_NAME} Interpretación del análisis
#!/bin/bash
trivy image httpd:2.2-alpine
2020-10-24T09:46:43.186+0200 INFO Need to update DB
2020-10-24T09:46:43.186+0200 INFO Downloading DB...
18.63 MiB / 18.63 MiB [---------------------------------------------------------] 100.00% 8.78 MiB p/s 3s
2020-10-24T09:47:08.571+0200 INFO Detecting Alpine vulnerabilities...
2020-10-24T09:47:08.573+0200 WARN This OS version is no longer supported by the distribution: alpine 3.4.6
2020-10-24T09:47:08.573+0200 WARN The vulnerability detection may be insufficient because security updates are not provided
httpd:2.2-alpine (alpine 3.4.6)
===============================
Total: 32 (UNKNOWN: 0, LOW: 0, MEDIUM: 15, HIGH: 14, CRITICAL: 3)
+-----------------------+------------------+----------+-------------------+------------------+--------------------------------+
| LIBRARY | VULNERABILITY ID | SEVERITY | INSTALLED VERSION | FIXED VERSION | TITLE |
+-----------------------+------------------+----------+-------------------+------------------+--------------------------------+
| libcrypto1.0 | CVE-2018-0732 | HIGH | 1.0.2n-r0 | 1.0.2o-r1 | openssl: Malicious server can |
| | | | | | send large prime to client |
| | | | | | during DH(E) TLS... |
+-----------------------+------------------+----------+-------------------+------------------+--------------------------------+
| postgresql-dev | CVE-2018-1115 | CRITICAL | 9.5.10-r0 | 9.5.13-r0 | postgresql: Too-permissive |
| | | | | | access control list on |
| | | | | | function pg_logfile_rotate() |
+-----------------------+------------------+----------+-------------------+------------------+--------------------------------+
| libssh2-1 | CVE-2019-17498 | LOW | 1.8.0-2.1 | | libssh2: integer overflow in |
| | | | | | SSH_MSG_DISCONNECT logic in |
| | | | | | packet.c |
+-----------------------+------------------+----------+-------------------+------------------+--------------------------------+ - Library: librería/paquete donde se ha identificado la vulnerabilidad.
- Vulnerability ID: Identificador de vulnerabilidad (según estandar CVE).
- Severity: existe una clasificación con 5 tipologías [fuente] las cuales tienen asignado una puntuación CVSS (Common Vulnerability Scoring System):
- Critical (puntuación CVSS 9.0-10.0): fallos que podría aprovechar fácilmente un atacante no autenticado y llegar a comprometer el sistema (ejecución de código arbitrario) sin interacción por parte del usuario.
- High (puntuación CVSS 7.0-8.9): fallos que podrían comprometer fácilmente la confidencialidad, integridad o disponibilidad de los recursos.
- Medium (puntuación CVSS 4.0-6.9): fallos que, aún siendo más difíciles de aprovechar, pueden seguir comprometiendo la confidencialidad, integridad o disponibilidad de los recursos en determinadas circunstancias.
- Low (puntuación CVSS 0.1-3.9): resto de problemas que producen un impacto de seguridad. Son los tipos de vulnerabilidades de los que se considera que su aprovechamiento exige unas circunstancias poco probables o que tendría consecuencias mínimas.
- Unknow (puntuación CVSS 0.0): se otorga a vulnerabilidades que no tienen asignada puntuación.
- Critical (puntuación CVSS 9.0-10.0): fallos que podría aprovechar fácilmente un atacante no autenticado y llegar a comprometer el sistema (ejecución de código arbitrario) sin interacción por parte del usuario.
- Installed version: versión instalada en el sistema analizado.
- Fixed version: versión en la que se resuelve el problema. Si no se informa la versión quiere decir que está pendiente de resolución.
- Title: Descripción corta de la vulnerabilidad. Para más información, consultar NVD.
Ya sabemos interpretar a alto nivel la información que nos muestra el análisis. Ahora bien, ¿qué acciones debería tomar? En la sección Recomendaciones te damos alguna pista.
Recomendaciones
En esta sección describimos algunos aspectos más importantes dentro del ámbito de vulnerabilidades en contenedores:
- Evitar (en la medida de lo posible) hacer uso de imágenes donde se hayan identificado vulnerabilidades critical y high
- Incluir el análisis de imágenes en procesos de CI
La seguridad en tu desarrollo no es opcional, automatiza tus pruebas y no dependas de procesos manuales. - Utilizar imágenes ligeras, menos exposiciones:
Las imágenes tipo Alpine / BusyBox están construidas con el menor número de paquetes posible (la imagen base pesa 5MB), lo que se traduce en una reducción de vectores de ataque. Soportan múltiples arquitecturas y se actualizan con bastante frecuencia.
- Evitar (en la medida de lo posible) hacer uso de imágenes donde se hayan identificado vulnerabilidades critical y high
REPOSITORY TAG IMAGE ID CREATED SIZE
alpine latest 961769676411 4 weeks ago 5.58MB
ubuntu latest 2ca708c1c9cc 2 days ago 64.2MB
debian latest c2c03a296d23 9 days ago 114MB
centos latest 67fa590cfc1c 4 weeks ago 202MB - Obtener imágenes de repositorios oficiales: Lo recomendable es utilizar DockerHub y preferentemente imágenes de publishers oficiales. DockerHub y CVEs
- Mantener actualizadas las imágenes En el siguiente ejemplo vemos un análisis sobre dos versiones diferentes de apache:
Imagen publicada el 11/2018
httpd:2.2-alpine (alpine 3.4.6)
Total: 32 (UNKNOWN: 0, LOW: 0, MEDIUM: 15, **HIGH: 14, CRITICAL: 3**) Imagen publicada el 01/2020
httpd:alpine (alpine 3.12.1)
Total: 0 (UNKNOWN: 0, LOW: 0, MEDIUM: 0, **HIGH: 0, CRITICAL: 0**) Como podéis observar, si un desarrollo finalizó en 2018 y no se realizan tareas de mantenimiento, podría estar exponiendo un apache relativamente vulnerable. No es un problema derivado del uso de contenedores, pero debido a la versatilidad que nos proporciona docker para testar nuevas versiones de productos, ahora no tenemos excusa.
- Especial atención a vulnerabilidades que afecten a la capa de aplicación:
Según el estudio realizado por la compañía edgescan, el 19% de las vulnerabilidades detectadas en 2018 corresponden a capa 7 (Modelo OSI), destacando por encima de todos ataques de tipo XSS (Cross-site Scripting). - Seleccionar imágenes latest con especial cuidado:
Aunque este consejo está muy relacionado con el uso de imágenes ligeras, consideramos hacer un inciso sobre las imágenes latest:
Imagen latest Apache (base alpine 3.12)
httpd:alpine (alpine 3.12.1)
Total: 0 (UNKNOWN: 0, LOW: 0, MEDIUM: 0, HIGH: 0, CRITICAL: 0) Imagen latest Apache (base debian 10.6)
httpd:latest (debian 10.6)
Total: 119 (UNKNOWN: 0, LOW: 87, MEDIUM: 10, HIGH: 22, CRITICAL: 0) En ambos casos estamos utilizando la misma versión de apache (2.4.46), la diferencia está en el número de vulnerabilidades críticas.
¿Quiere decir que la imagen basada en debian 10 convierte en vulnerable la aplicación que ejecuta en ese sistema? Puede que si o puede que no, hay que evaluar si las vulnerabilidades pueden comprometer nuestra aplicación. La recomendación es utilizar la imagen de alpine.
- Evaluar el uso de imágenes docker distroless
El concepto distroless es de Google y consiste en imágenes docker basadas en debian9/debian10, sin gestores de paquetes, shells ni utilidades. Las imágenes están enfocadas a lenguajes de programación (Java, Python, Golang, Node.js, dotnet y Rust), contiene exclusivamente lo necesario para ejecutar las aplicaciones. Al no disponer de gestores de paquetes, no puedes instalar tus propias dependencias, lo que se puede traducir en una gran ventaja y en otros casos, un gran obstáculo. Realizad pruebas y si encaja con los requisitos de vuestro proyecto, adelante, siempre es beneficioso disponer de alternativas. El mantenimiento corre a cuenta de Google, así que el aspecto de seguridad estará bien acotado.
Ecosistema de analizadores de vulnerabilidades para contenedores
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
Ángel Maroco llevo en el sector IT más de una década, iniciando mi carrera profesional con el desarrollo web, pasando una buena etapa en distintas plataformas informacionales en entornos bancarios y los últimos 5 años dedicado al diseño de soluciones en entornos AWS.
En la actualidad, compagino mi papel de arquitecto junto al de responsable de la Pŕactica Cloud /bluetab, cuya misión es impulsar la cultura Cloud dentro de la compañía.
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar